
Name and Shame
Yes, a rant as well as a brief departure from the ongoing and super-duper exciting (ahem) series on data loading . It’s going to feel great – for me; it may also be instructive – for you. Seriously, read this and ponder if this post doesn’t reflect your practice. If it doesn’t, it really should.
And oh yes, this one is dedicated to my objectively younger taller and most definitely smarter and subjectively better looking brother, Celvin Kattookaran. He writes great code, but there is one itsy witsy bit that he misses…
Comments as in code
If you read the last post in this series, as you surely did, you’ll remember the bit about using a flat file’s file name to create a unique data load SourceID to ensure that data from multiple files in the same Import Workflow Profile Child and thus Data Source didn’t go bye-bye. Important Stuff, to be sure.
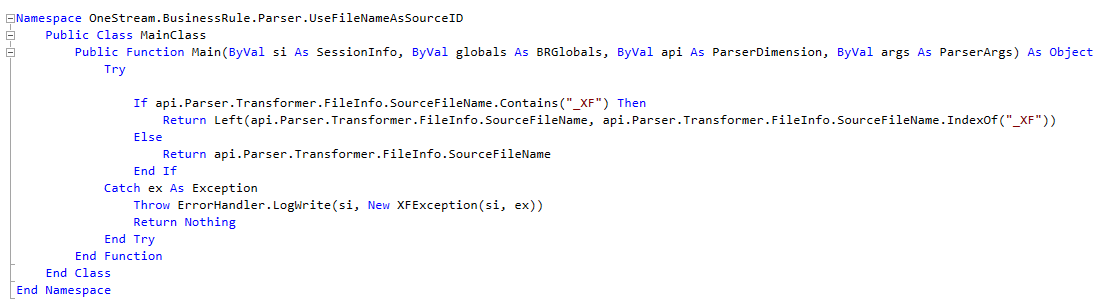
I noted in that post that I didn’t write the code, I had the code, I thought everyone-ish had the code, and that Tom Shea himself wrote it. That’s: yes definitely, Ibid., not really, and nope. Two out of four isn’t all that terribly bad, but not altogether good.
Why Cameron, why, why, why?
The above code works, but why? It’s sort of a pathological obsession with Yr. Obt. Svt. – I must understand what makes something tick, whatever it may be. If I understand the why, I can figure out the how, and the how is what I use to earn my daily crust. Also, it prevents me from making even larger mistakes than usual. Neuroses aside, understanding what code does is useful because it really and truly prevents mistakes.
Let’s slap a log message in there to see what happens in the code:

And load it:
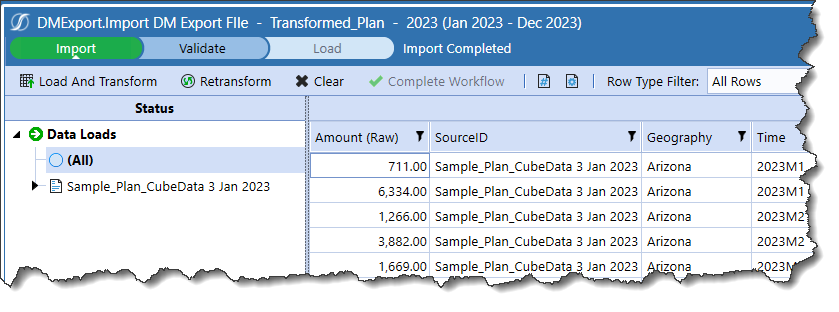
Here it is:
Crikey, that took a long time for a 25k csv file. It shouldn’t take more than a second or so:
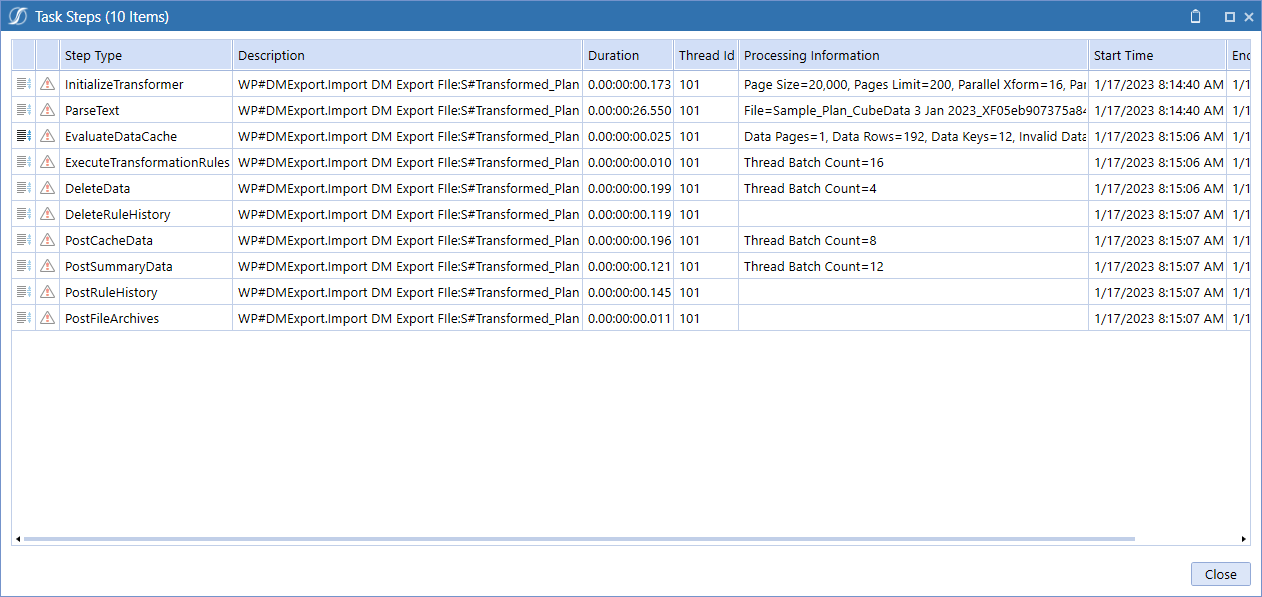
Oh dear, oh dear, oh dear, 26 ½ seconds to parse 194 records is sort of amazing in a bad way but that’s because each record is being interrogated and logged. That logging performance cost is why one should always ensure that logging is either commented out (temporary) or simply remove it from code (permanent) when not needed.
What do we get for our logging?
The logging fired for each and every line of the Data Source. That of course makes sense as OneStream parses the file line by line. Given 194 records, two messages per record, and an expensive BRApi.ErrorLog.LogMessage, 27ish seconds doesn’t seem all that bad.
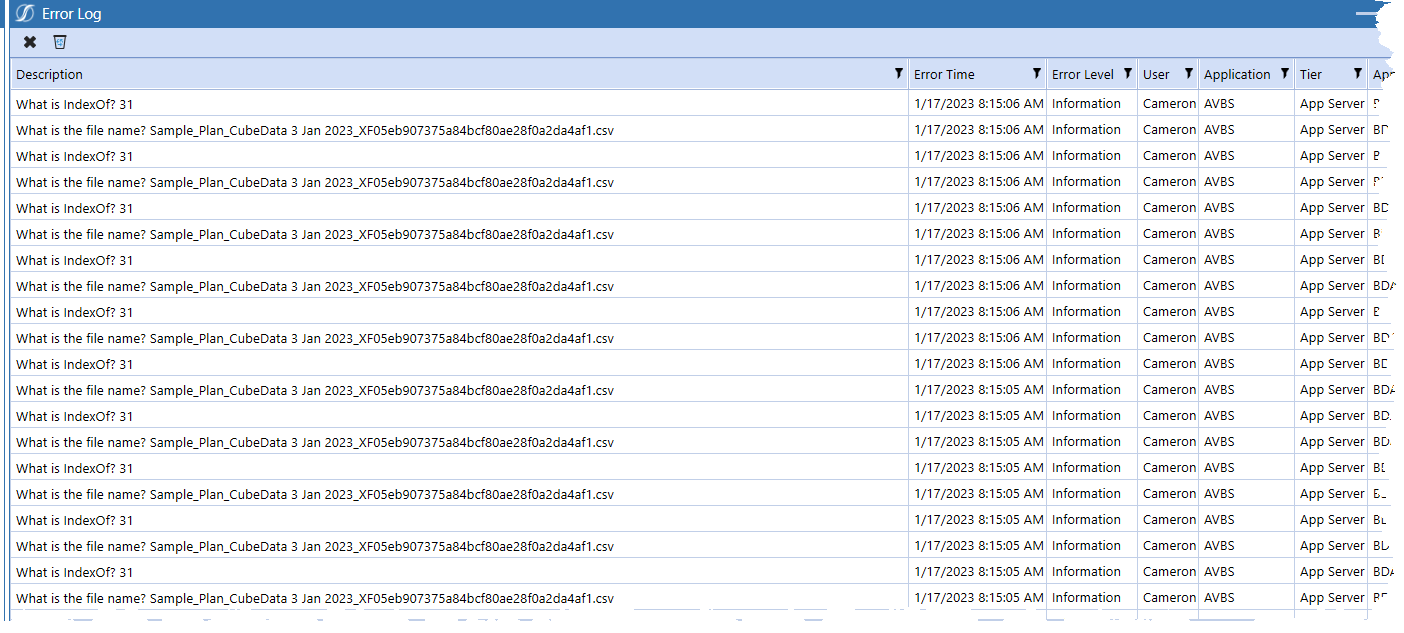
Note the spectacularly long OneStream-generated GUID after the _XF characters.
But why care about this? Not getting rid of a _XFGUID in the SourceID shouldn’t really matter should it?
Well, yeah, it does
The GUID OneStream generates is unique in that its possible values has a domain of undecllions which is 1036 if using short scales or 1066 if using long. That ought to be as close to unique as near as damnit.
A pause: the above has to be some of the most esoteric yet potentially useful information I have ever put into a blog post and that count is well over 300 in over 14 years of inflicting my madness on the blameless public. You win. Or lose. You’re welcome.
My math geekiness aside, OneStream’s GUID is for all practical purposes unique. What will not be unique is data if the same file is loaded more than once.
Let’s take out that test for _XF and trim and instead just use the file name:

Big oops
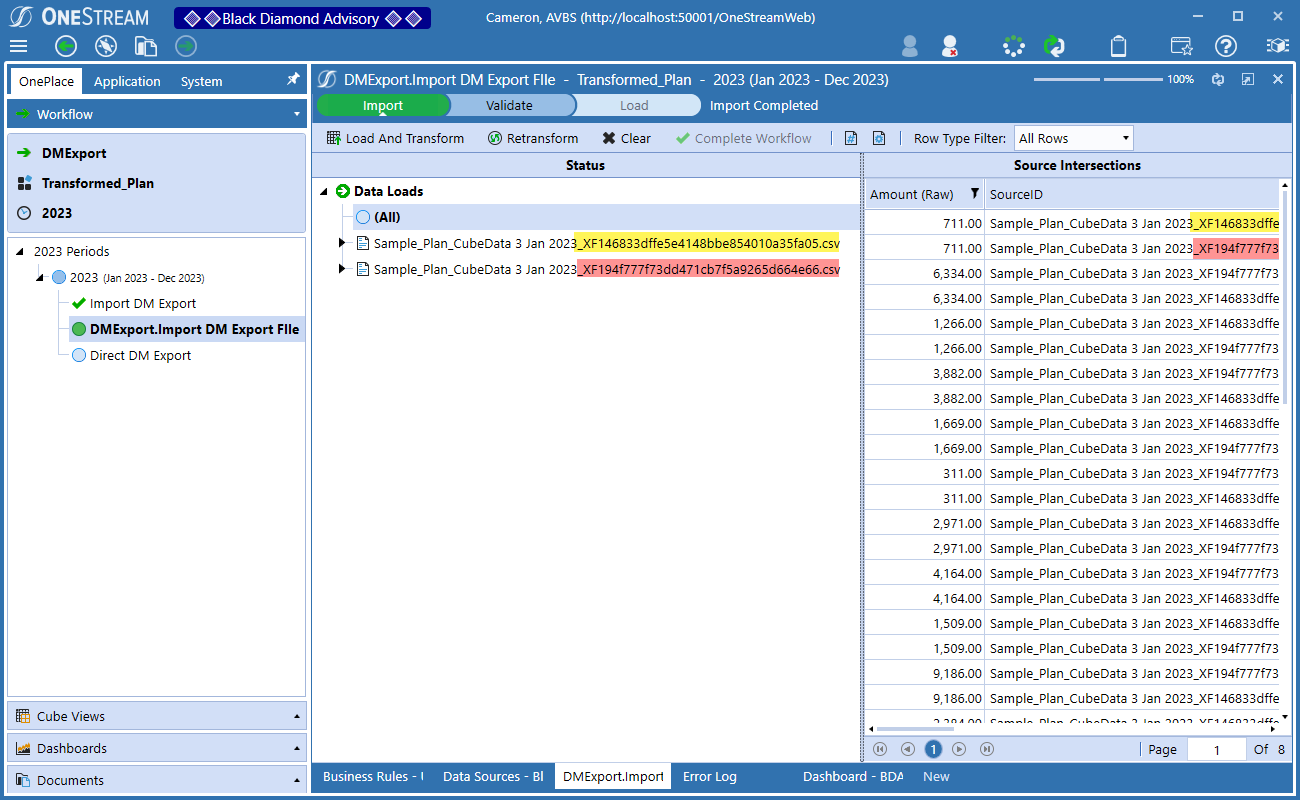
There’s 711 (I am a Philly native, born and bred, so I am a Wawa fan. I will not enter into the intense Pennsylvanian rivalry around Wawa vs. Sheetz as we Philadelphians know which is best by far.) twice. How? Why?
A second pause: beyond my terrible convenience store pun, the above must surely be some of the most esoteric yet completely unnecessary information I have ever put into a blog post. I’m sorry. And I’m right. You’re welcome.
Readers of the part 3 of the Exporting to Import series may recall that the file name acts as a unique identifier. When the SourceID is duplicated the first load’s data is replaced with that subsequent file’s data. This is a Good Thing.
However, when the GUID is not removed, the SourceID is unique and thus it can load once, twice, forever, or at least till an undecillion before it repeats which is unlikely given drive space, interest, and all of our life spans combined, and that means extra – and wrong – data.
So that’s what it’ all about: strip off the GUID to allow reloads. Excellent. Awesome. Prima.
No good deed goes unpunished
While writing this post was fun, and the code is absolutely vital, my mordant curiosity would have been much easier if it had been commented. Something like this – minus the snark – would have told me everything I need to know:
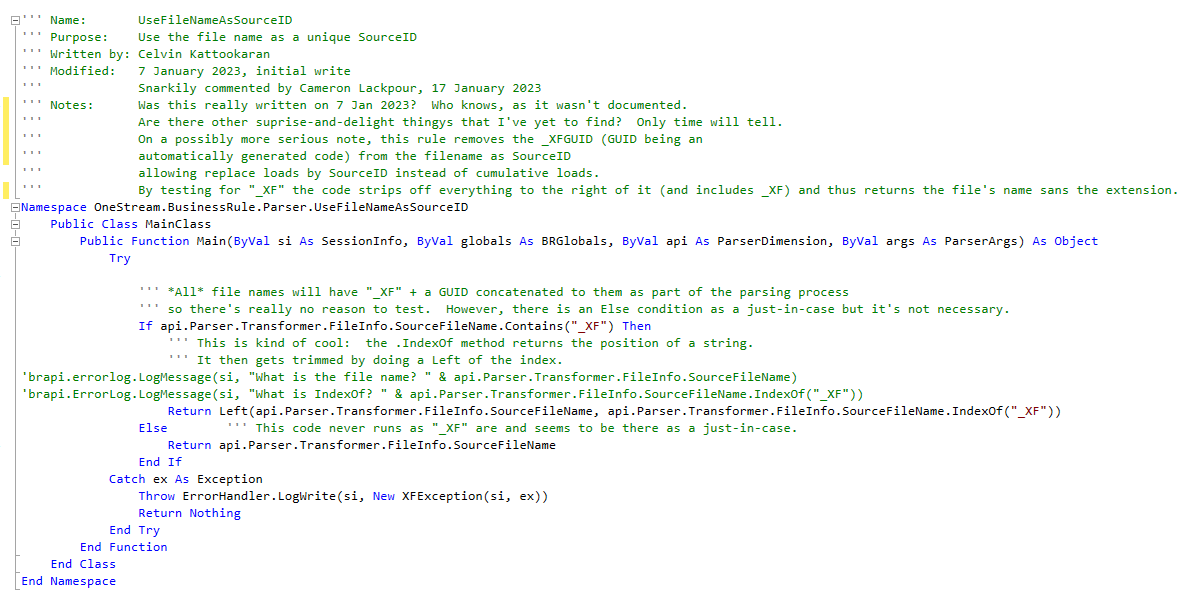
The comments tell the reader: what, why, who, when, and where. The how comes along for free with the rest of it.
That gift horse
So should you care if code is commented or not? Celvin wrote a useful, nay vital, bit of code. It does its job, is efficient (I have seen other versions of this that are many lines longer), and just works. Quite seriously, thank you Celvin. But I still wish you had commented this.
Think of it this way: it took me about five minutes to rip every bit of five code lines apart. What if it had been 500? 5,000? For the math adverse, 5,000 lines of code a minute a line is 83 1/3 man hours. Eeek. What those 5,000 lines of code had to be modified and none of it was documented? Someone will have to figure it out. May that someone never be me. Or you.
Would commenting the code take an equal amount of time? Even my verbose style doesn’t take that long. Think of the next guy three months from now. Think of yourself. Be concise in your comments, but be complete.
Be seeing you.

