Now that we have some experience in creating a SQL statement to query OneStream’s backend data record tables, we can now focus on some other aspects that would also tie into an end-to-end SQL solution. Here we’ll cover loading a relational table with data (outside of the staging tables) and querying that data to tie into existing sales information already loaded to OneStream.
Why would we do this?
Let’s imagine there’s some large data source outside of what is already being loaded to OneStream. Within this large data source, there are also a variety of metadata dimensions required to calculate some values for some FP&A process but aren’t required for formal reporting.
In my mind, there are two different paths that we can go down here:
- The usual OneStream Method
- The relational table method
The usual OneStream method usually involves these steps:
- Configure a data source to match the data required for the FP&A process
- Load in the necessary metadata members into a custom dimension used specifically to calculate values required by the FP&A process (could be thousands of members)
- Configure a transformation rule to maybe do any special transformation, conforming to the dimensionality currently within OneStream
- Load the data through a workflow profile
- Write a business rule with a data management job or formula directly on a member to calculate the values into desired final calculation members (using the previously loaded custom dimensionality, which may even involve creating intermediary members to get to a final calculation)
The relational table method would go something like this:
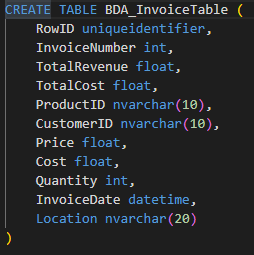
- Configure a relational table with the same columns as the data extract using a `CREATE TABLE` SQL statement.
- Load data into that table using `BRApi.Utilities.LoadCustomTableUsingDelimitedFile`
- Write a SQL statement to calculate the values required by the FP&A process that loads into a vb.net data table
- Write the output to a csv file
- Load using a workflow profile (with configured data source and necessary transformation rules)
Now, the main deciding factor on whether to go down either path is heavily reliant on what metadata is required to calculate the values needed in the FP&A process. If a metadata dimension inside of the large data set contains something like 100,000 unique products along with another metadata dimension with 50,000 unique customers, then it’s probably better to go down the relational table method if formal reporting doesn’t require this granularity (especially if you are proficient in writing SQL statements).
The reason I say this is mainly due to the definition of a data unit within OneStream – and without going into too much detail – basically, loading in 100,000 different products into a UD dimension will only cause performance headaches in the future (especially if this granularity is only ever used for one or two specific FP&A processes). To understand this a bit more, there’s a great data article on OneStream Community that you can read.
Moreover, doing calculations on very large datasets (500k+ rows) within the database is usually very performant if you write the SQL statement right.
The relational table method
Loading Data into a relational table
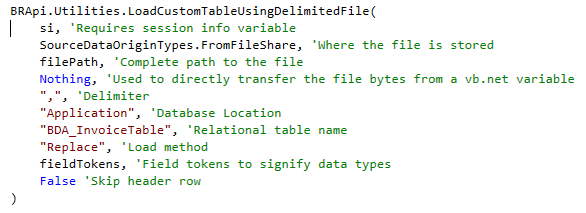
OneStream has conveniently provided a function to load delimited files to relational tables, which is intuitively called `LoadCustomTableUsingDelimitedFile`.
Used like so:
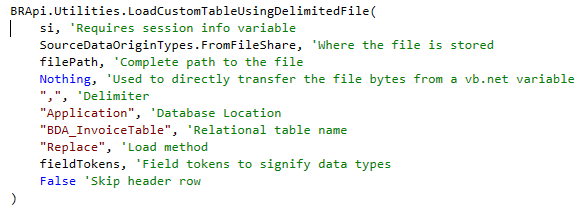
There are a few important nuances for this function.
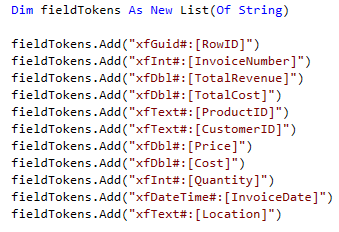
- You need to explicitly define the data types for each column through a list of strings that OneStream is calling ‘field tokens’
- There are several load methods, the one we will be using here is a replace, which replaces the entire table on every new load.
Refer to the Design and Reference Documentation to get more detail on field tokens and load methods.
Here’s an example of adding field tokens:
And a create table statement to go along with it (no need to get fancy here, unless you really need to):
For the smaller things like getting the exact file path for the csv file programmatically, I’ll leave out the detail for that, as I think it’s a good exercise to really understand how file paths work in OneStream (especially if you’re on a cloud instance).
Here’s an example of what your csv file might look like (without a header):
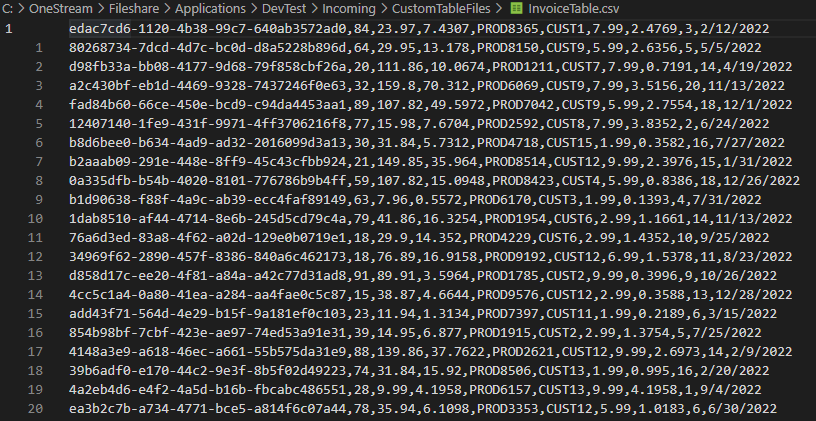
Note: You’ll notice I have a GUID as a row ID, generally it’s a good idea to have something that uniquely identifies every row in the data set. It could be a GUID like I’m using, or it can just be a simple integer increment, use what makes sense for your use-case.
Once you run the business rule (either through an extensibility rule or a dashboard extender), your file should be loaded.
For a quick check, you can create an ad-hoc data adapter:
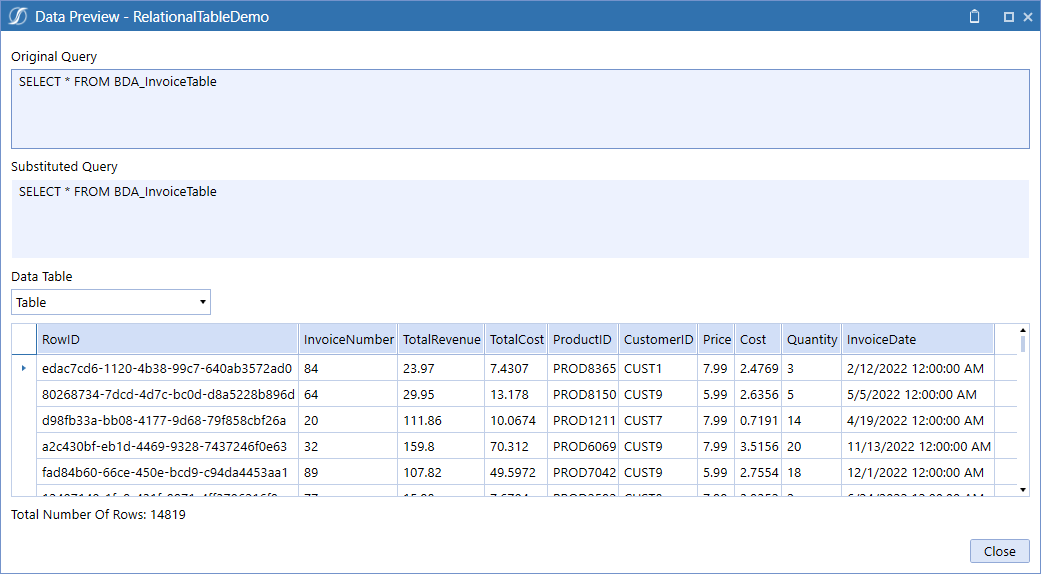
You want to do… what now?
Let’s imagine some FP&A requirements for planning:
- The business needs to capture all invoices with customers buying quantities over 20 for any singular product.
- Once captured, we need to get the last 10 most recent invoices in the year to track the cumulative revenue for those invoices.
- FP&A needs to keep a running tally of which customers have cumulative revenue totals that pass a threshold of 1500 dollars and aggregate the amount for an entire location.
- Once calculated, the value must be posted to the GL Account `CustomerLoyalty`
Let’s implement this in SQL:
First, we get all invoices with quantities over 20 for any singular product:
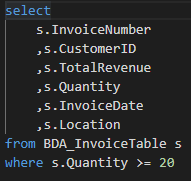
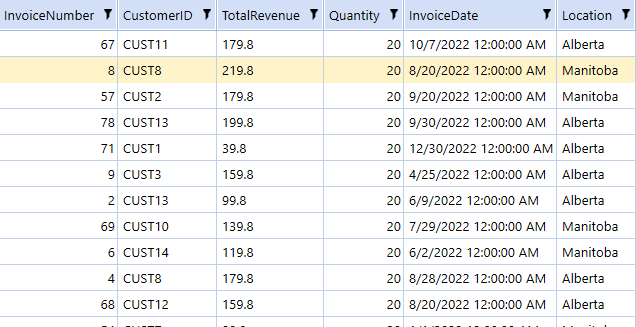
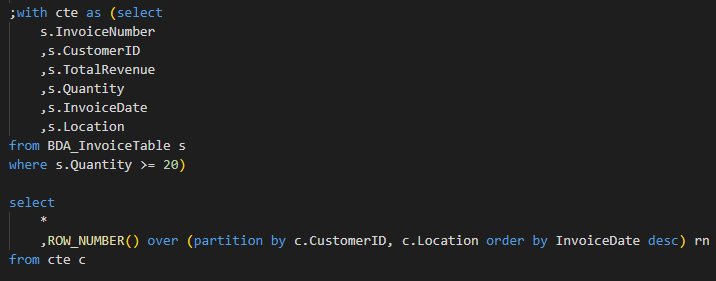
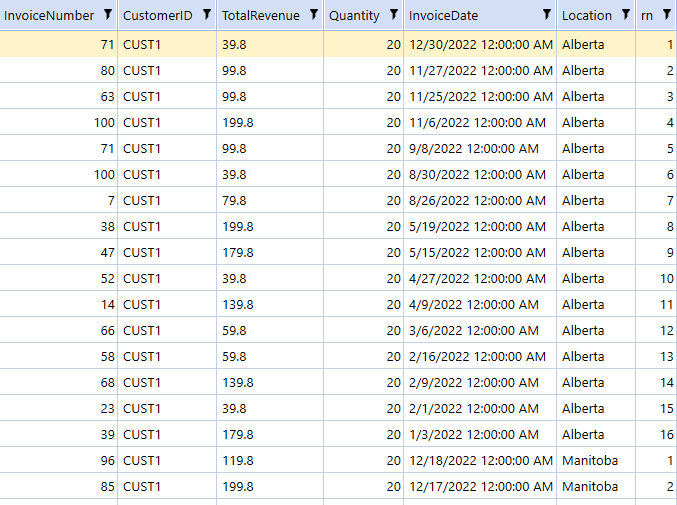
Now let’s order the invoices by most recent for each customer:
Now grab the first 10 along with the cumulative sum:
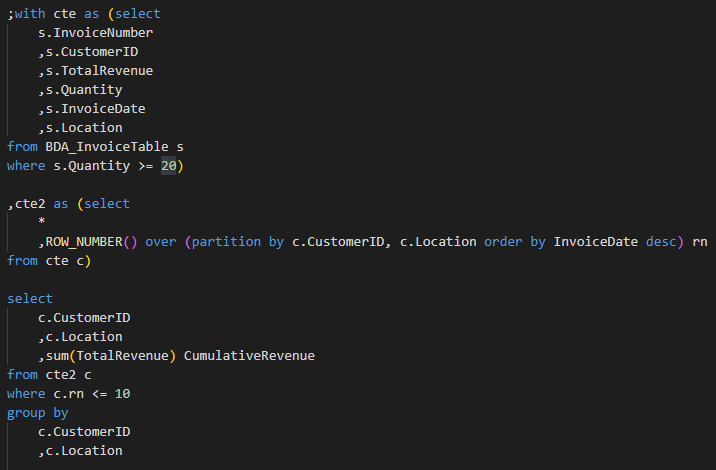
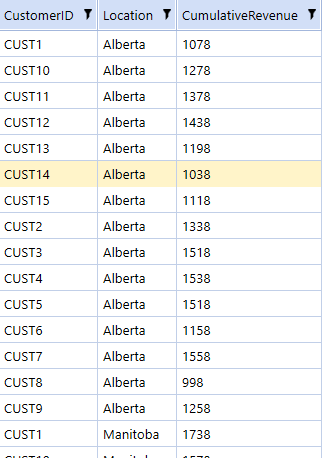
And finally, filtering out cumulative revenue under 1500 and getting the total value for all customers:
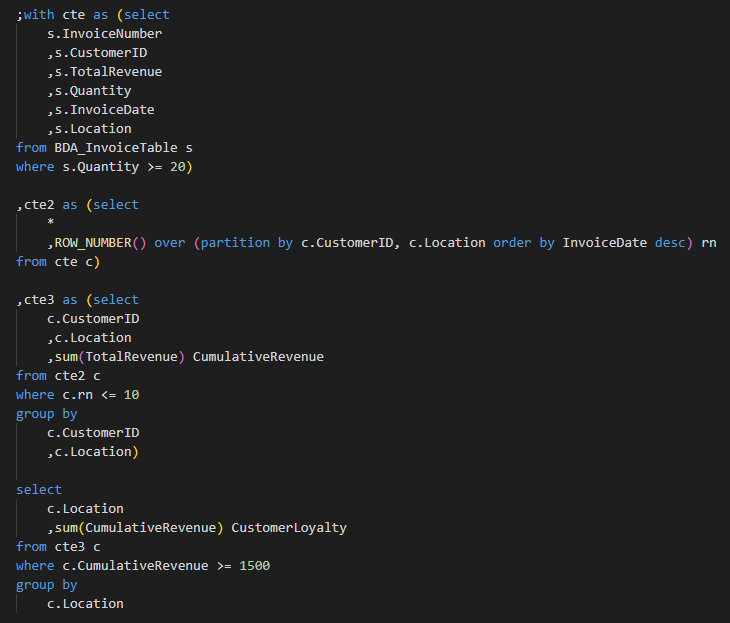
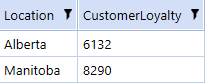
And we’ve done it – we can now load this into a data table using `ExecuteSql` like so (where the `sql` variable is a string containing the SQL statement above):

If the result set is large, you can take that data table and write it to a csv file, which you would then load through a workflow profile. In this case, however, you may want to just use an `api.Data.SetDataCell` to set these values for the specific GL account and location intersection.
Merging the calculations with cube data
In addition to just posting the values to the GL account, the FP&A team also wants to keep track of the percentage of total revenue (already in OneStream) for this customer loyalty calculation.
We can use the SQL statement that we created in Part 1 as well as creating another common table expression:
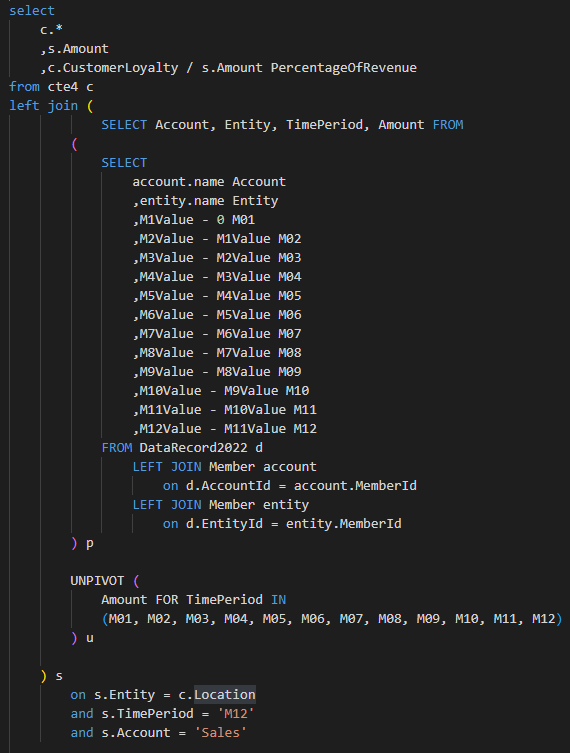

I have hardcoded M12 in here, but as you can imagine, if this sits on a data management sequence or a dashboard, you can pass the |WFTime| variable to make this dynamic.
The Possibilities are Endless!
I have yet to encounter an FP&A process that I couldn’t convert to a SQL statement; I’m sure there are some out there that would give me a bit of trouble, but usually they’re things like what I have shown above. A lot of the effort in developing a SQL solution comes from just really knowing your data and the techniques at your disposal to manipulate the data at will.
The one thing that I have noticed – and that I want to emphasize – is that when you do these calculations in SQL, they perform really fast, especially if you make use of common table expressions like I have done.
And obviously the process that I have done above doesn’t just apply to an instance where something needs to be calculated and thrown into a GL account. You can also have a full-fledged BI solution using OneStream dashboard components where very complex (or simple) SQL statements would feed the backend.
Hopefully, this series gave you a bit more perspective on implementing those pesky FP&A processes.
Until next time.