
How Many Connector Rules Do We Really Need?
Not as many as you may think (or were taught)
Fellow OneStream enthusiast, if your list of OneStream Connector Business Rules looks like the below then this blog is for you. If it doesn’t, I hope you still find it useful or at least mildly interesting!

Figure :Why, oh why, did I not see the light earlier?
Now I must confess, many of my early solutions looked like this: it is the common and generally taught method and it feels like the natural way to set Connector Business Rules up due to the way we link a DataSource to a Connector Rule.
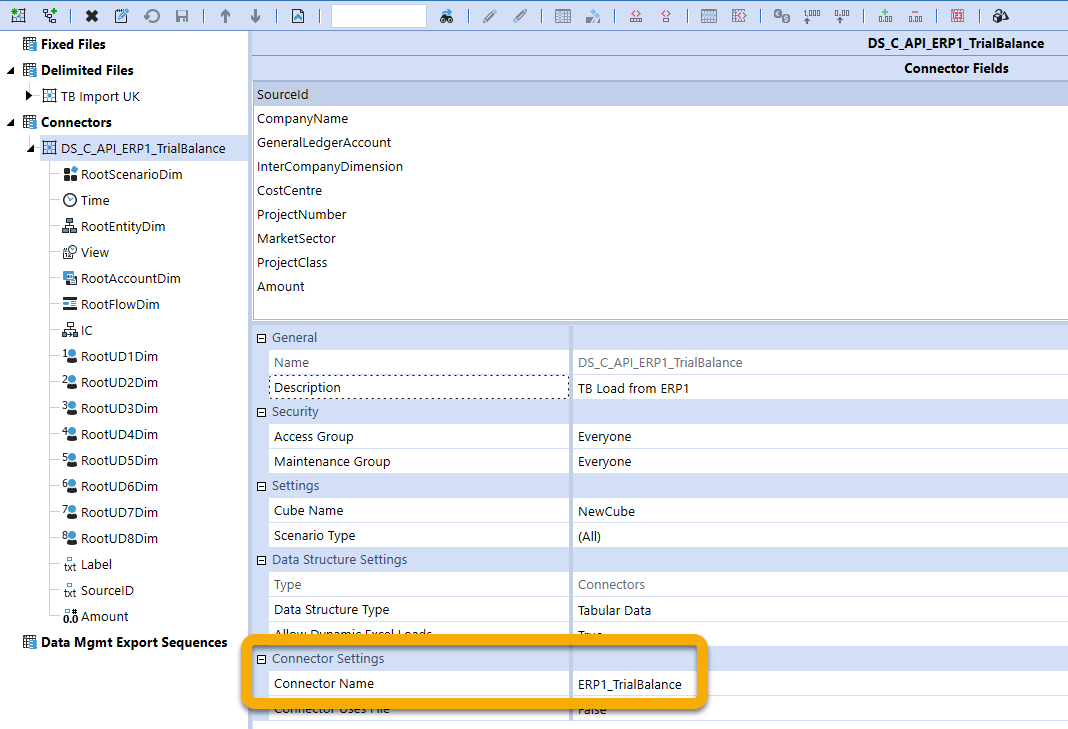
Figure : The old way, one rule per DataSource
The Epiphany
As you may be aware I am an inherently lazy developer have a strong preference to build reusable functions wherever possible. It was as I was creating a myriad of API connector rules for a client that I realized the error of my ways. Most of the logic in these rules is the same, declare a source database connection, call that connection, get the data and return it to the stage.
Why, I asked myself, if I have a standard OAuth2 security handling function in an extender rule to save me the hassle of rewriting facilitate standardization am I copying pasting and tweaking the same rule over and over?
As you read through this post, you will (hopefully) come to understand why a lazy developer is a good developer: writing and testing core functionality and then reusing it means said developer produces quality solutions, does not go bonkers with boredom writing nearly-identical code ad infinitum, and is now free to go onto bigger and better things. This practice actually is not laziness, it is competence. And laziness.
One Rule to Rule Them All
How do we do it?
Having had my epiphany moment I set about deleting all the connector rules I had created to that point (to avoid the temptation to just continue with what I had created and force me to deliver something new) and set about creating one to rule them all. For this blog I will be using REST APIs as the example which returns JSON data, however the same methodology is applicable to any source type, be it API, SQL, SAP, FTP, and so on.
But how does the rule know what to connect to and what the data looks like?
There were two key items in creating a single rule and making it work that I considered first; how does the rule know which DataSource is initiating it and how do we flex the fields returned.
Getting the DataSource Name
This is easy enough, when a DataSource in OneStream (or (almost) anything) calls a business rule the action knows what told it to do something. In a connector rule this is in the args object.

Figure : But where do we get the DataSourceName, oh, there it is
The name of the DataSource for the import process is captured in args.DataSourceName. Problem one solved!
Structuring the data, data field types
My preferred method here is to use custom classes created within the connector business rule.
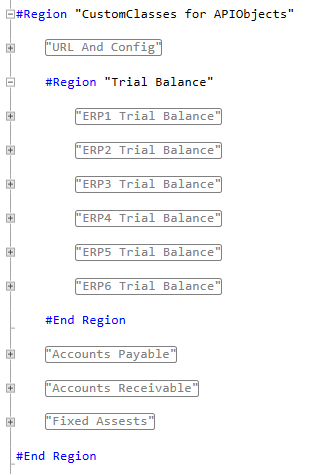
Figure : Give a class a home
The Example
For brevity we will show two API calls, but this methodology will work with as many as you like. Additionally, because we are only looking at two examples, I am going to keep the logic simple. As the volume of sources increases, I would advise additional optimization of the code. For example, one rule to hold the logic, another to hold the classes and a config file to hold the connection details.
I love a class
Without further ado let’s go look at one of the Trial Balance classes.

Figure : Each DataSource needs two classes
First off you may notice I have lied to you (I will try not to do this again), we create two classes here, not the one I led you to believe.
- The first is a simple flat object used to provide the field list to the DataSource for mapping fields to dimensions, additionally used to create a datatable to hold the flattened JSON string returned by the API.
- The second represents the nested JSON structure returned by the API, this is how our friend Newtonsoft.Json knows how to deserialize the nested JSON string. I may have forgotten to mention we need additional References to make all this work.
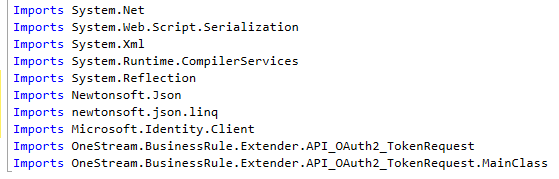
Figure : The additional References we need for this connector methodology
The key ones I will explain here are Newtonsoft.Json (explained above), Microsoft.Identity.Client (required if you have an OAuth2 protected API) and the last two which are the beginnings of my epiphany moment. This is a Business Rule in OneStream in the Extender section that I use to manage all OAuth2 security token calls.
Getting the fields
To get the field list for the DataSource we just need to utilize the class we created and return these to the Main function. Within this you can see that we have our first use of args.DataSourceName which is used to return the correct class object for the DataSource. Then we just use a For-Each loop to loop through the class, add the field names to a List and return this:
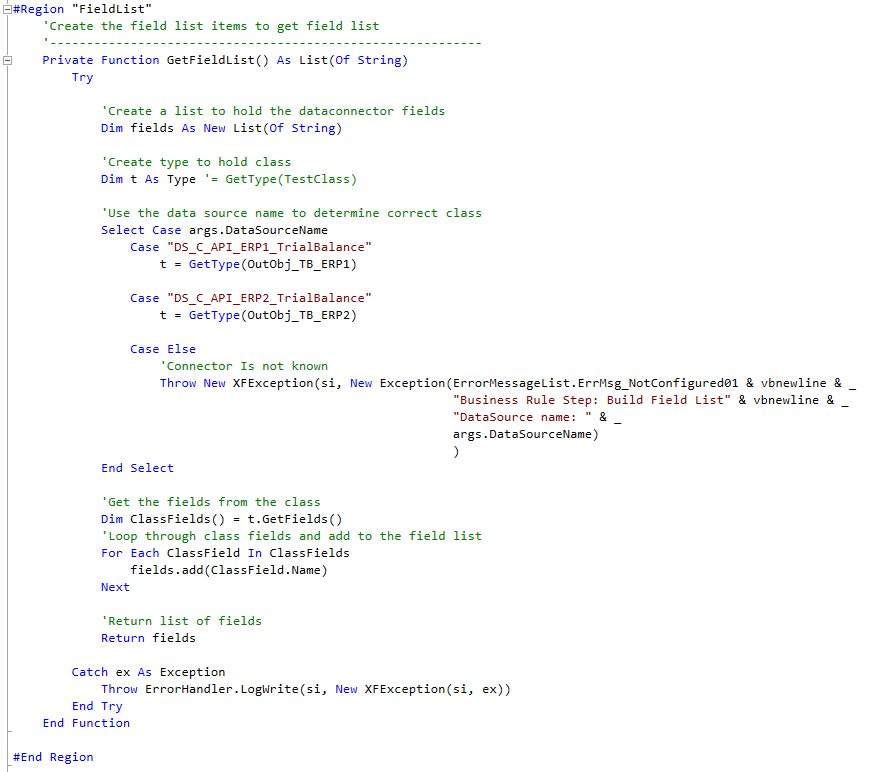
Figure : Getting the fields from our classes
Et voilà, we have field names in our DataSource to map to our Source Dimensions.
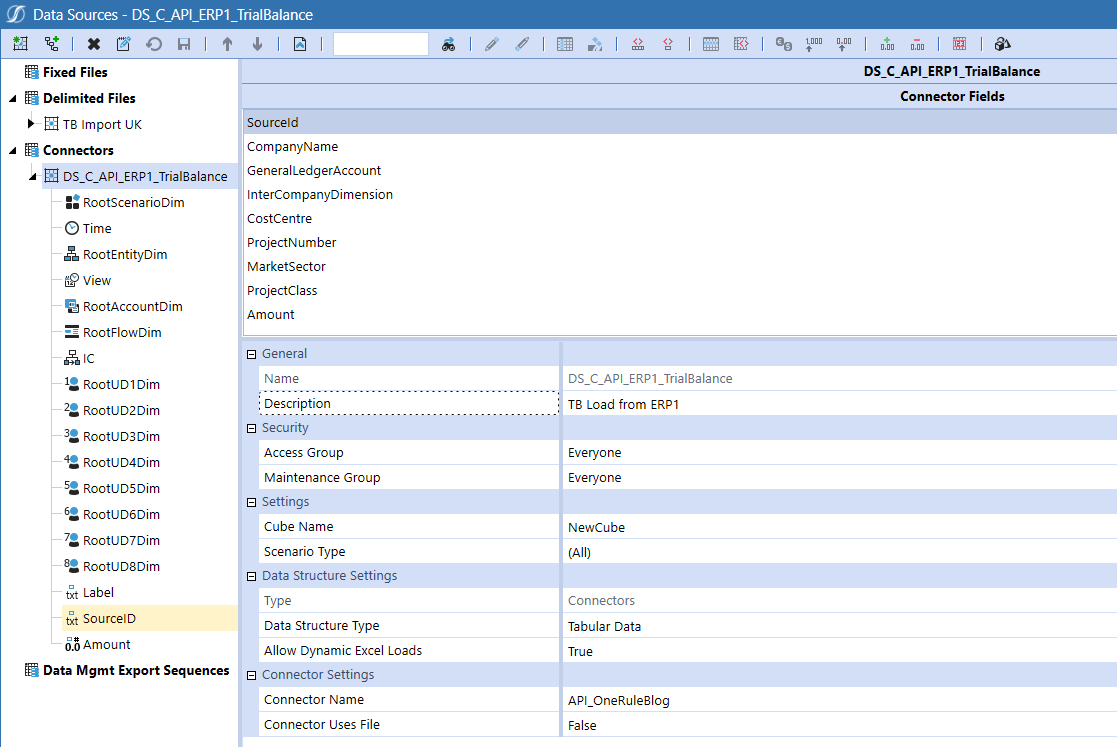
Figure : We have fields to map!
The URL
Often a URL will have additional components required to identify or filter the records we require. Below is an example of how this could look.
https://apicalls.mydomain.com/SendTBFromERP1ToOneStream?company=myCompanyID&postingEndDate=myPeriodEndDate
Where the items in blue may vary, not exist, or have additional elements. We vary these by a simple use of dictionaries and passing in the items we need for the API to accept our call.

Figure : Handling varying URL components

This will generate a URL string like the below:
- https://apicalls.mydomain.com/SendTBFromERP1ToOneStream?Company=BlackDiamondAdvisory&PostingEndDate=20221231
- https://apicalls.mydomain.com/SendTBFromERP2ToOneStream?Company=BlackDiamondAdvisoryUKLtd&StartDate=20220101&EndDate=20221231&Fixed=True
The Data
Finally, the data, which is why we’re all here I assume.
For each DataSource we use the relevant Class Object to manage the deconstructing of the nested JSON data into a flat data string. Following this all we need to do is to create a datatable to put the data in and then return it to the stage.
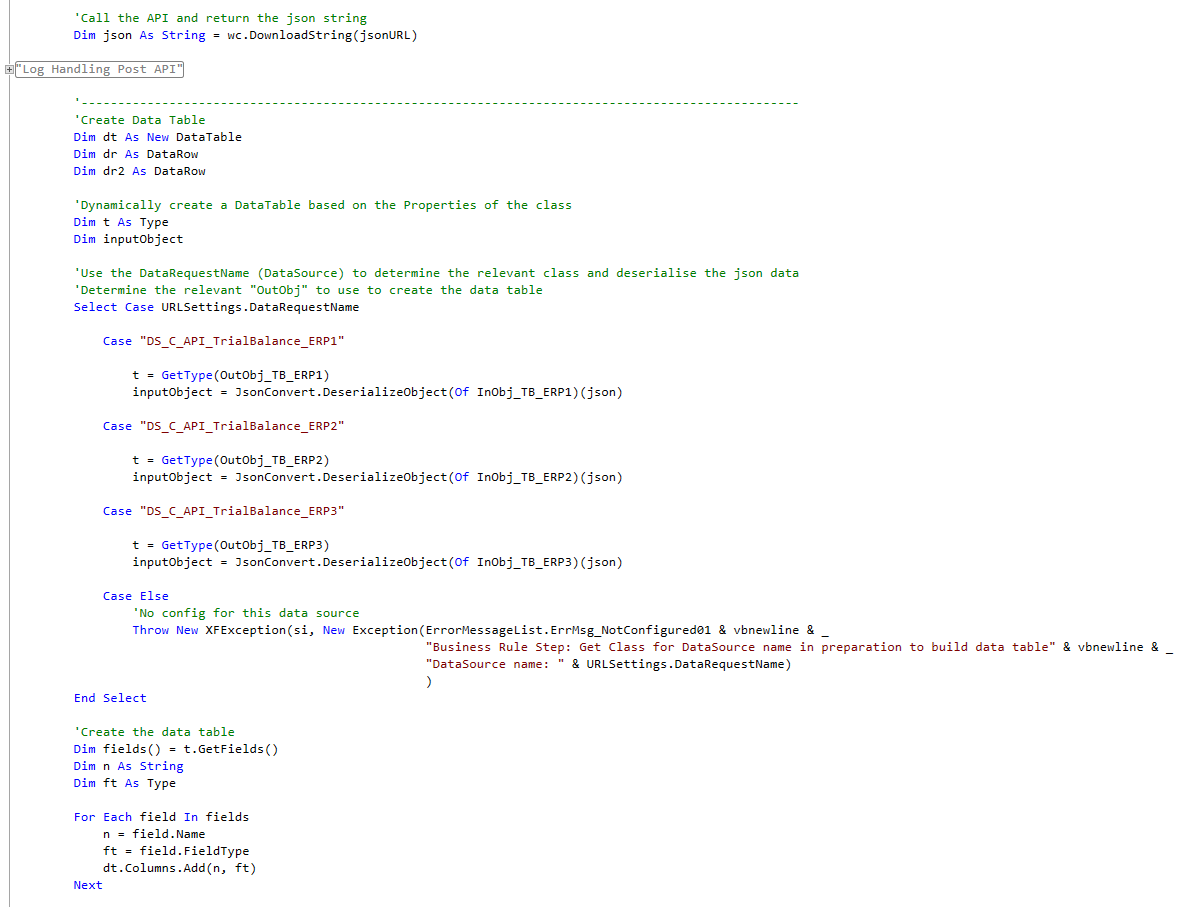
Figure : Get me some data!
The Conclusion
As always with OneStream there are at least five ways to do anything. The above is just one illustration of simplifying Connector Rules.
A key factor in making the above methodology a success is to start by identifying the source databases, URL endpoints and/or fileservers needed for data. Please do take into consideration that there may be additional sources required after you and your initial build is in Production! Categorize these into sources that make sense to group together and go from there. The categorization is completely up to you. My recommendation is to think along the lines of source type, for example, REST API v SQL, etc. and/or by Source End Point. For example, if you have 10 imports from multiple systems (TB, FA, AP, AR, etc.) maybe it is the right mindset to create a rule for each system.
One thing is for sure, save yourself time and stop creating a rule for each DataSource!