How data loads work, coz it ain’t necessarily what you think
Loading data into a Cube results in that data in the Cube. Loading additional data into said Cube (think of a new data point although the nuances of this get tricky as we shall see) results in the old data being retained and the new data as well. Data gets loaded; it sticks around. New data gets loaded; the old data sticks around and so does the new. Easy peasy, isn’t it? Except it isn’t because it doesn’t, not always.
A note (one of many in this post): I had planned on this post in the data load series showing how the four different Data Load Import methods act. However, the deeper I dove into how just Plain Old Replace works (really any of the methods), I realized I had to cover the core data load subject in more detail. Thanks must go to My-Bruvver-From-Completely-Different-Parents as he explained, not for the first time, how the Level2 Data Unit and Workflow interact and then how Replace and multiple Workflow Profile Children (siblings) interact and then how SourceIDs within the same Workflow Profile Child Import interacts. Do I ever understand any of this? Do I? Maybe? In my defense, OneStream’s behavior is kind of mind-blowing. And interesting. And vital for all of us to know.
With that, let’s begin the journey.
Stupidity, stupefaction, and siblings
NB – Much of what I’m about to describe is expected behavior for accountants-who-do-OneStream, i.e. that strange, green visored collection of geeks that actually understand double entry accounting. I am – as must be obvious by now and will certainly be so once you’ve read the next section – not one of them.
Stupidity
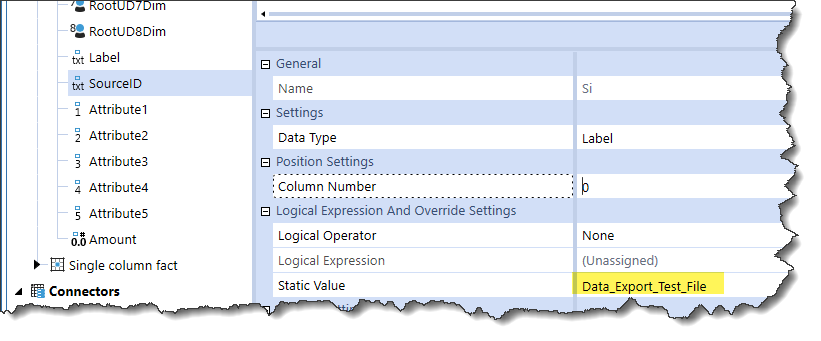
Because Laziness and Stupidity, Yr. Obt. Svt. created a Data Source with a hard coded SourceID.
This is just fine when loading a single data file.
Assuming a 192 record data file that comes from the first post in this data series (I ran the export, went into File Manager, and downloaded the file to my local drive), I should be able to easily load data and so it is.
In OneStream:
And in Excel:
Here’s the next file. It’s 2023M1, in Pennsylvania, and is 10_020’s Sales:

Stupefaction
Here’s 2023M1’s data before I do a Replace load:
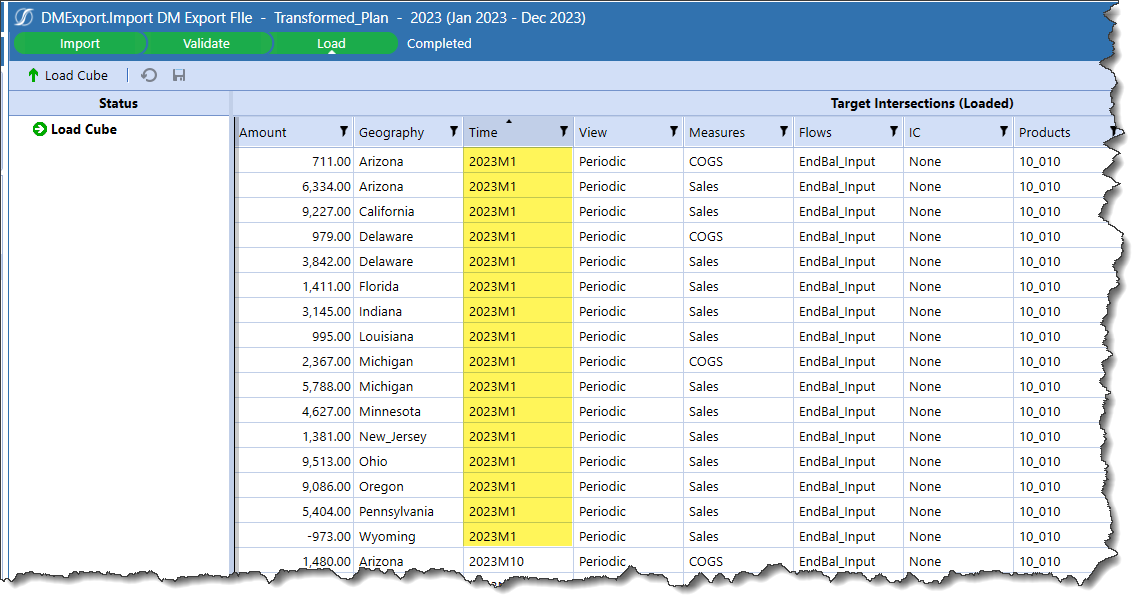
My expectation is (was) the 2023M1 data is not touched because the data intersection from this single record data load does not intersect. But…
Oh dear, oh dear, oh dear

All of the prior data in 2023M1 across multiple Level 1 Data Units are gone in Stage as well as the Cube:
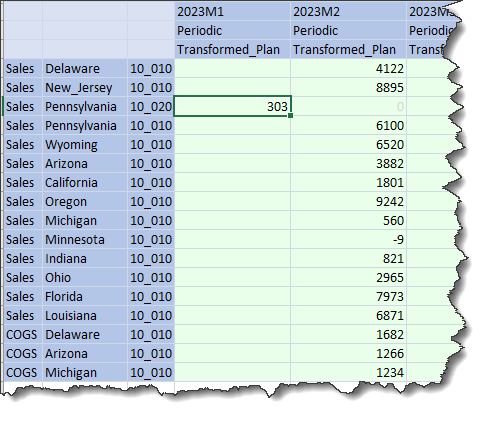
At least 303 is in the Cube, but this is most definitely not what I wanted. Again, Consolidations Practitioners will likely not be shocked by this, but we Simple Folk of the Planning Universe will be dismayed.
Sibling Workflow Profile Import Children
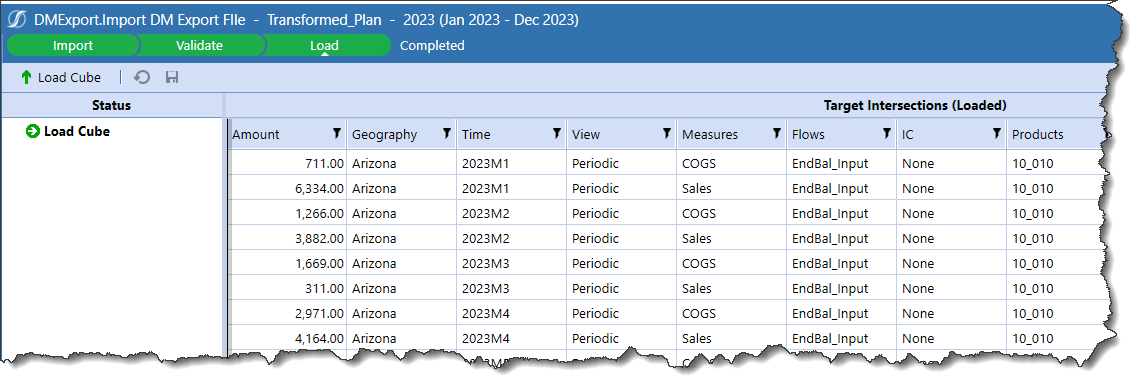
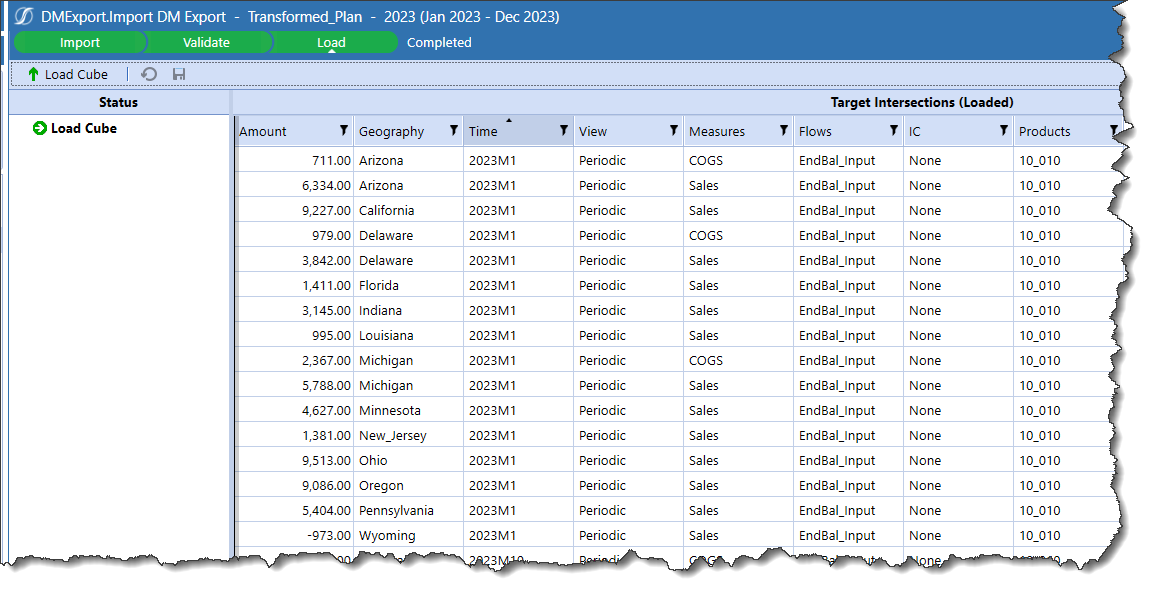
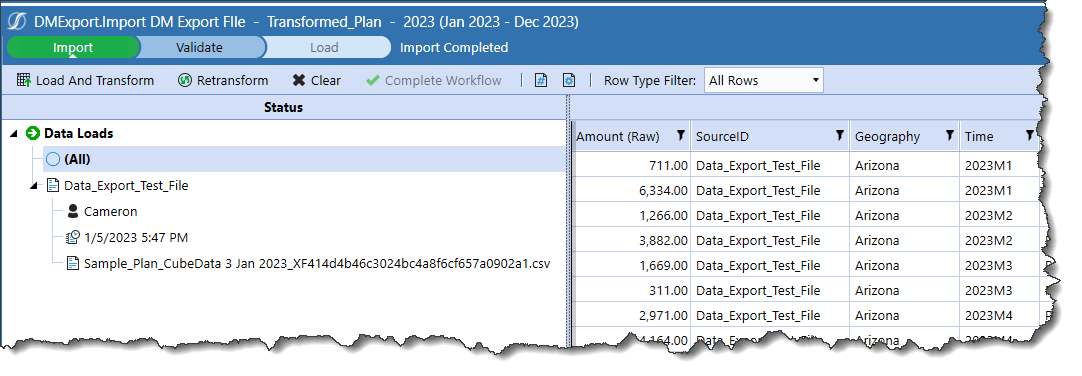
I did a Scenario Reset, and then went back to my Import DM Export Workflow Profile Child which runs a Data Management export and then import and returns the first result:
And in Excel:
I’ll now load the data in Import DM Export File:

2023M1 data in Stage in Import DM Export is not changed. Huzzah!
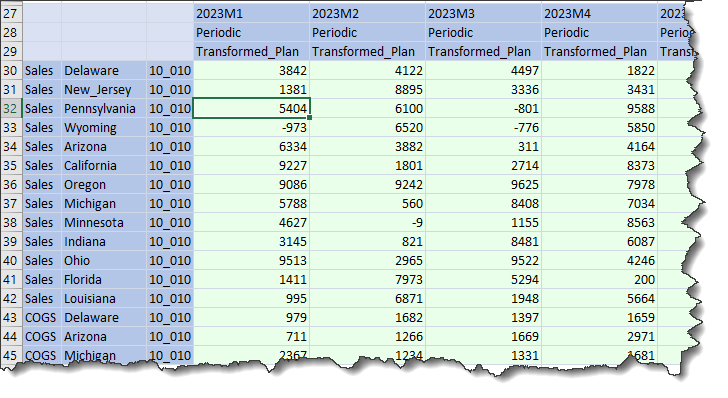
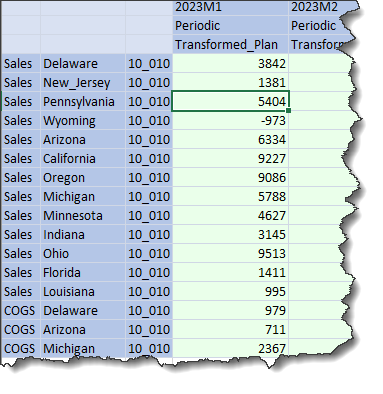
And in Excel:
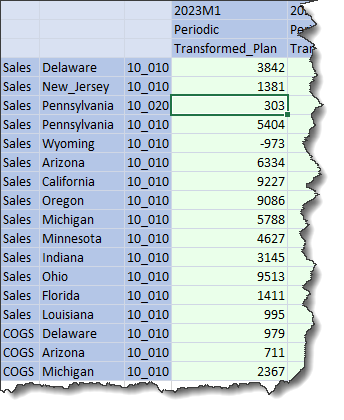
Not only has the rest of the 2023M1 data not disappeared, but the new 303 data value has been loaded. Huzzah, again.
But what’s going on?
SourceIDs
After a huge amount of experimentation, aka trying everything I could possibly think of until something approaching the right result occurred and driving poor Celvin mad with questions, I finally realized that SourceID acts as a key to stage data. If using sibling Workflow Profile Children acted as a key, then SourceID could likely as well.
To continue the technique of loading in Workflow Profile Child, each file would need its own SourceID. A lovely thought, except of course the SourceID within the Data Source was fixed. What to do?
When OneStream imports a file, it identifies the filename and displays it in the Status pane. If OneStream can pick up that filename, and my data comes in via multiple data files, it seems that capturing that filename and then making it the SourceID value will result in the filename being that key. With a unique SourceID key, OneStream will (hopefully) preserve data that shouldn’t be cleared on a Replace load.
How then to read the file name to populate the SourceID field? Ask and ye shall receive.
Enter the code that (almost) everyone has
I know that I didn’t write this code. I’ve heard that Tom Shea himself wrote it although I cannot remember who told me that and I will note that he documents his code and there is none, so maybe not. I believe that every (probably) consultant at every (probably) consultancy has this code. I now share someone else’s (thank you, whoever you are) extraordinarily useful Parser Rule code:
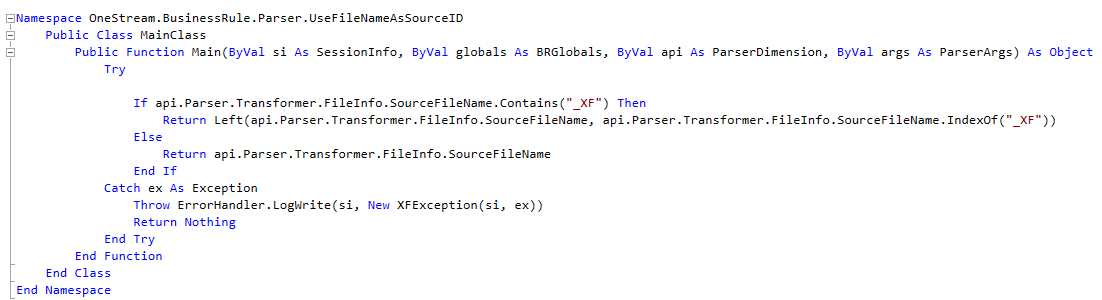
Here it is in text form for your copying and pasting pleasure. As always with free things, test, test, test before you use this in anger.

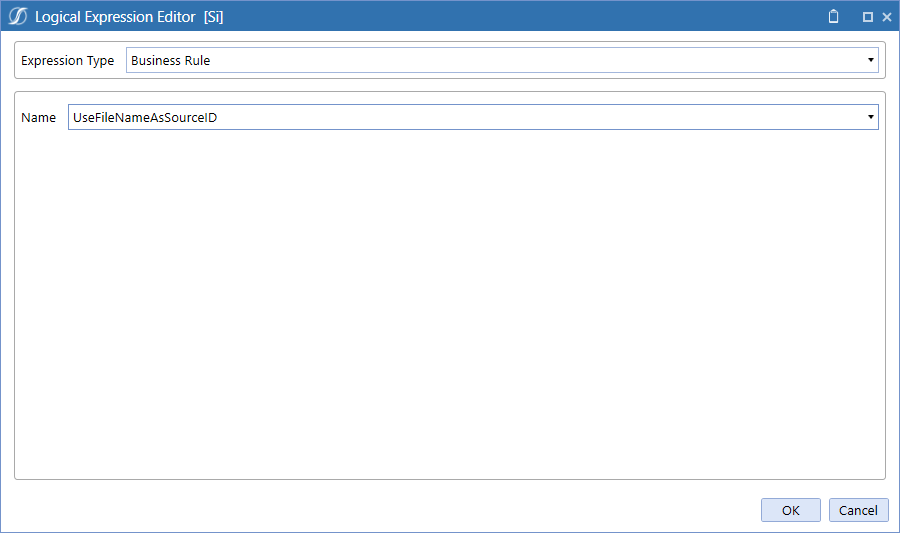
With that caveat, create a new Parser Rule, name it UseFileNameAsSourceID, save it and then ready, set, go.
Namespace OneStream.BusinessRule.Parser.UseFileNameAsSourceID
Public Class MainClass
Public Function Main(ByVal si As SessionInfo, ByVal globals As BRGlobals, ByVal api As ParserDimension, ByVal args As ParserArgs) As Object
Try
If api.Parser.Transformer.FileInfo.SourceFileName.Contains(“_XF”) Then
Return Left(api.Parser.Transformer.FileInfo.SourceFileName, api.Parser.Transformer.FileInfo.SourceFileName.IndexOf(“_XF”))
Else
Return api.Parser.Transformer.FileInfo.SourceFileName
End If
Catch ex As Exception
Throw ErrorHandler.LogWrite(si, New XFException(si, ex))
Return Nothing
End Try
End Function
End Class
End Namespace
And now assign it to the SourceID field:
Only Parser Rules will show up:
Once saved, what happens?
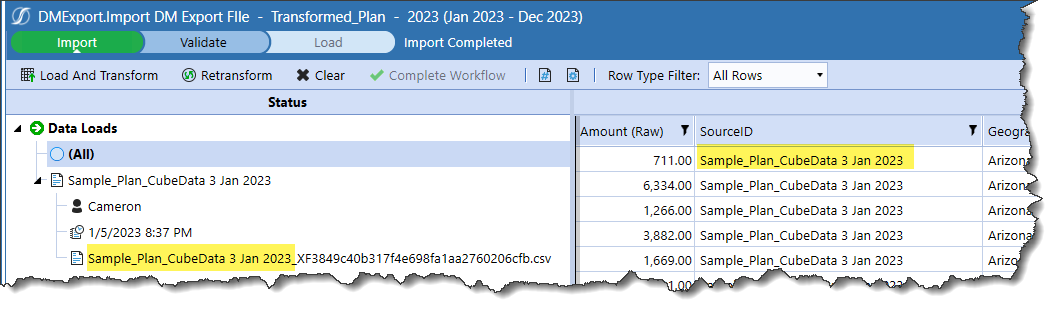
The file name is now the SourceID. What happens when a second file is loaded?
Here it is in its own SourceID:
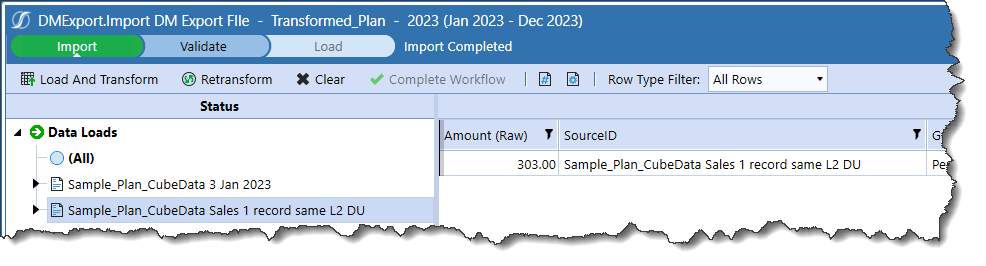
And alongside Sample_Plan_CubeData 3 Jan 2023:
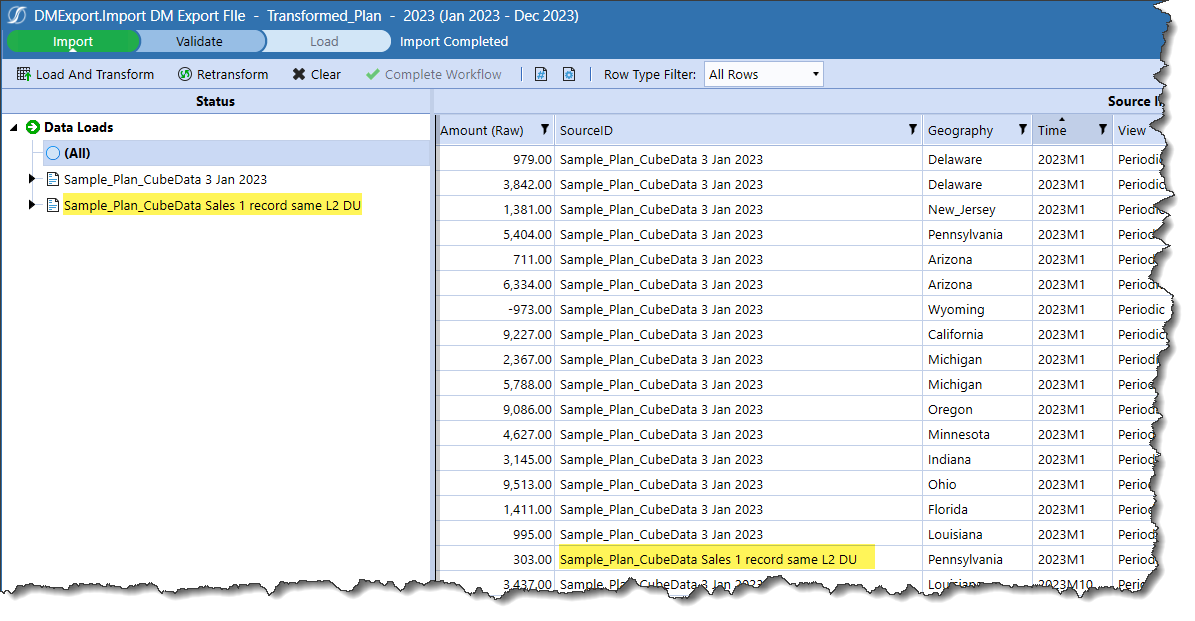
In Excel:
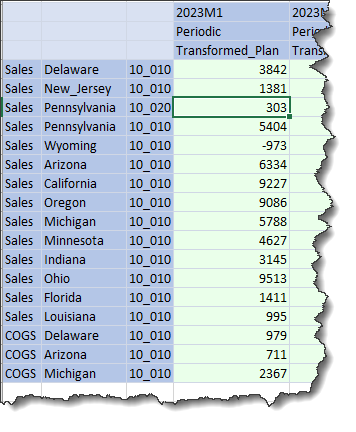
Huzzah! Again!
Is our long national nightmare over? Maybe.
Understanding the Level 2 Data Unit. It’s important, really important.
The Level 1 Data Unit is made up of Cube, Entity, Scenario, Time, Consolidation, and Parent. You, I, we happy OneStream Practitioners are all aware of it for it governs how data is addressed. There is another (actually there are three but this blog post won’t go that far) level, and its behavior is not totally straightforward.
The Level 2 Data Unit is the Level 1 Data Unit plus Account. Somewhat ominously, it is known as the Workflow Data Unit.
The OneStream Design and Reference Guide states (emphasis added). “The Level Two Data Unit is the default level used by the Workflow Engine when controlling, loading, clearing, and locking data. This indicates when data is loaded from the staging data mart to the Cube, it is cleared and locked at a level of granularity that includes the Account Dimension by default.”
It also notes (emphasis added yet again), “For example, if two Import Workflow Profiles are not siblings of the same Input Parent, but load to the same Entity, Scenario and Time, data will be loaded and cleared at the Account level. Consequently, if these two Workflows load the same Accounts, the last Workflow Profile to load will win. However, if these two Workflow Profiles load to different Accounts, data will load cleanly for both Workflow Profiles.”
What does all of this mean? Simply that if different Workflow Profiles are used and data loads to the same Level 1 Data Unit and to a different Account, data loaded through those different Workflow Profiles is retained.
Here’s data in Pennsylvania, 2023M1, Distribution, and 10_020. Note that Distribution has never been loaded. This is a brand new Level 2 Data Unit.

In a new Workflow Profile and a new Import Workflow Profile Child:
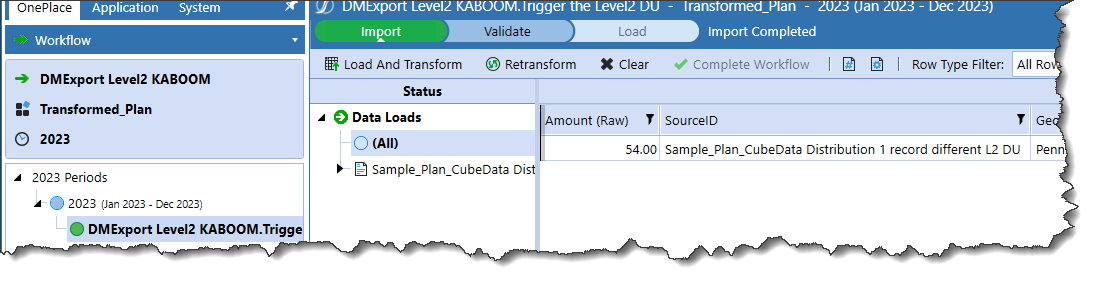
Here’s my the distribution value of 54:
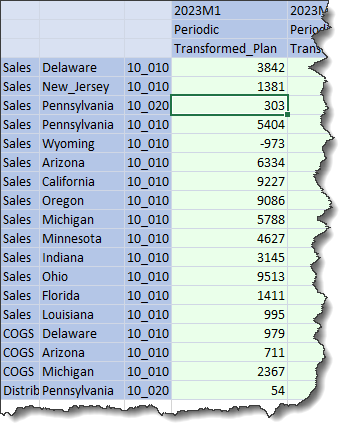
What happens now if COGS data is loaded to Pennsylvania Sales 10_020 in this separate Workflow Profile? This is another load to an existing Level 2 Data Unit.

It’s nice to see the SourceID pick up the filename so Stage doesn’t get zapped, not that it’s going to help any:
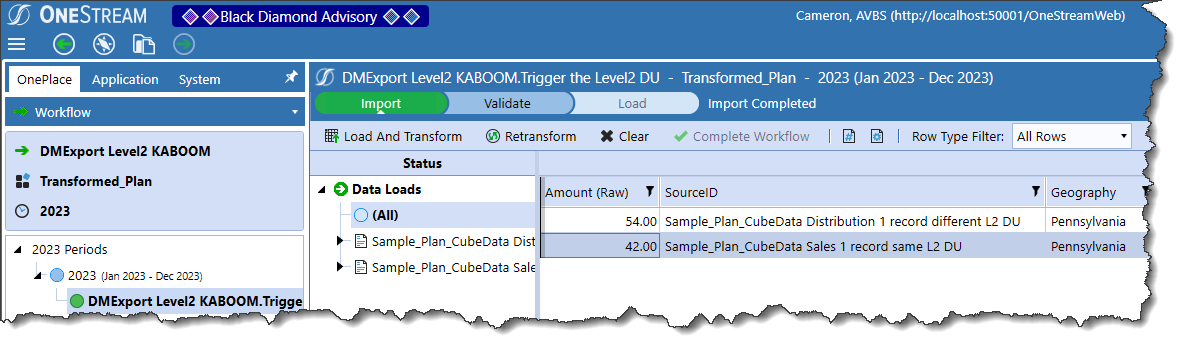
But what about a load to the Cube? Oh dear, oh dear, oh dear.
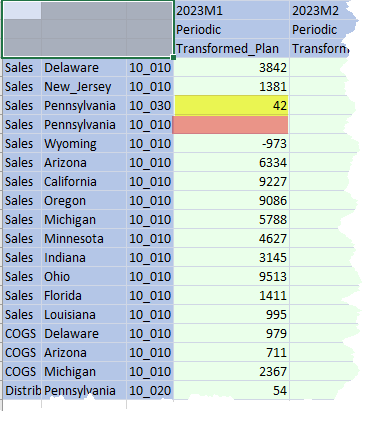
42 is loaded, but 303 is gone. Such is the capricious nature of the Level 2 Data Unit. Entity, Time, Account, etc. were all the same but the second load was at 10_030, not 10_010, and thus a load to an existing Data Unit across Workflow Profiles, thus (again) triggering the Level 2 Data Unit clear, just as the Design and Reference Guide said it would.
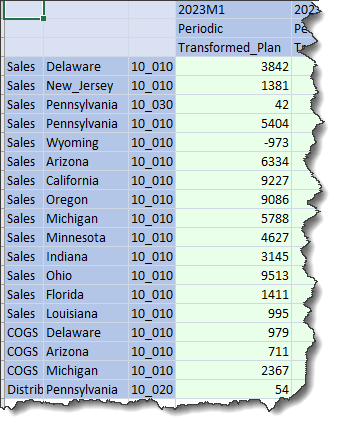
What happens if all of this happens within the same Import Workflow Profile Child?
And what happens if we load this across sibling Import Workflow Profile Children?
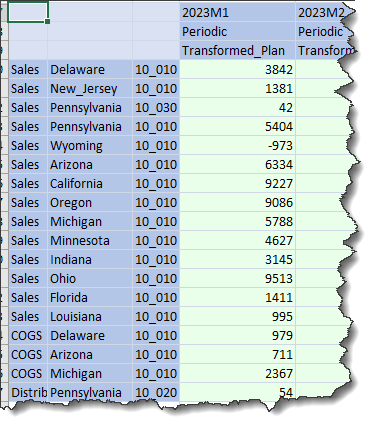
It can be done, one must just know how, like practically everything else in life, OneStream or otherwise.
What have we learnt, Cameron, other than you can become quite obsessed about things like this?
Yes, this data load behavior drove me absolutely, positively, completely bonkers. Thank you, OneStream. Or is it me that should be thanked? Dunno. I do know it took me an awfully long time to write this (14 pages and counting in Word) and even longer to figure it out. I’m not totally sure who benefits from my mad obsession, but I suppose I kind of enjoy it. I think.
What all of this means for you and the next few posts on this export-to-import series is this:
- Multiple data sources can be loaded across sibling Import Workflow Profile Children with a static Data Source SourceID.
- Multiple data sources can be loaded within a single Import Workflow Profile Child with unique SourceIDs.
- Level 2 Data Unit clears may occur if multiple data sources are loaded across different Workflow Profiles.
- Level 2 Data Unit loads will not trigger a data clear if they are loaded within the same Import Workflow Profile Child or in sibling Import Workflow Profile Children.
After a bit of struggle, we see that life is not all a bleak and dreary existence, but we must take care when loading data lest it go bye-bye when least expected.
Whew, that was a lot, but it’s important to understand how OneStream loads data, and the rules aren’t particularly hard to follow.
Be seeing you.