
Is there really any question here? Why?

Different technologies seem to have different data format predilections. In my Previous Technology Life, a relational data source was the default: secure, curated, managed, fast, flexible – I could go on and on but you get the idea. Whether extracted by IT in a data stage environment or brought together with some (at least if I wrote it) mildly-not-totally-garbage-but-probably-so SQL, relational data sources were (and still are) the standard for companies, cf. Microsoft SQL Server, Oracle, IBM DB2, MySQL, etc. So why doesn’t that seem to be the case with OneStream? Dunno, as the first word in CPM is Corporate. But much of life’s meaning escapes me or I refuse to listen to other people or perhaps, just perhaps, I’m right in my assertion. Stranger things have happened.
And yes, before anyone objects, relational data sources can be slow if not managed properly (do not read a trillion row fact table if you need 100 records), but then again so can anything else in any other product.
With that deeply satisfying rant out of the way, perhaps the reason OneStream data sources are not commonly relational is because of their perceived complexity: a flat file is just there – open it up in Notepad++ or Excel or whatever and see it. A relational data source needs to be connected and that means – gasp – a Connector Business Rule to bridge the gap between OneStream and the data. Fear not, because it’s easy peasy to do so and it is flexible in a way that a flat file cannot be.
It’s time for you to pay attention
A note and a very serious one: this blog post uses a table that contained within the OneStream application database. Queries against external databases for cloud customers (so just about everyone except for Yr. Mst. Hmbl. & Obt. Svt.) must have their connections defined by OneStream Support — you can’t do it on your own unless you are a blogger running OneStream on his laptop or a rare on-premises customer. Most if not all corporate data sources will be of this external kind. Baby steps first with an internal table, especially since the code difference itself is beyond trivial.
Every journey needs a start, this is ours
Imagine a table that looks suspiciously similar to an export from a OneStream Cube:
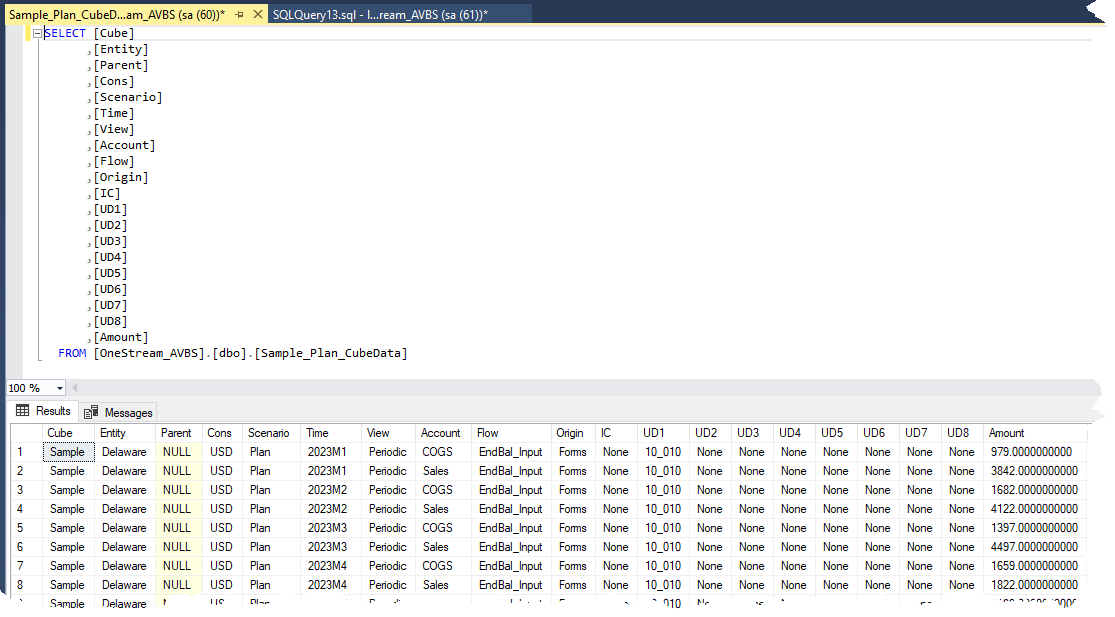
A Data Source needs to understand the fields to match them against the dimensions and then when loading, needs to read the table’s records. That’s it.
Getting the fields with code
Ah, the dreaded Connector Rule. Fear not, Gentle Reader, as this is just two simple-ish steps.
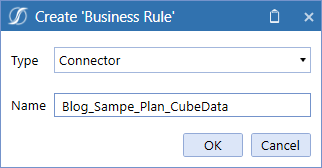
Create the Connector Rule
Do I really need to spell this out? The compulsive documenter in me says, “Yes!” so here we go when a new Business Rule is created:
Action Stations
Oh dear, oh dear, oh dear, this initial Business Rule isn’t very helpful, is it?
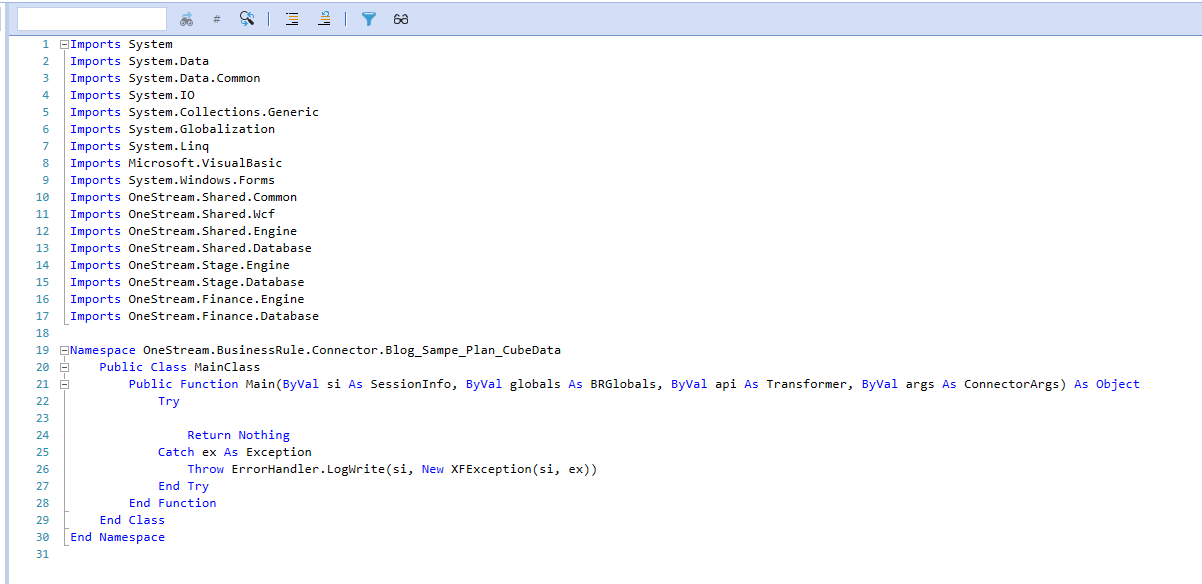
What we need is an args.ActionType to capture two ConnectorActionTypes: GetFieldList (the first step) and GetData. Simplicity-ish itself, if you’re a complex sort of geek.
ConnectorActionTypes.GetFieldList
The Data Source needs a list of fields. They could come from a List(Of String) that is explicitly named, e.g., lstFields.Add(“YourFieldNameRightHere”) or one could be lazy and have the relational source return the field names. I prefer this approach because the list of fields will be used in the query against the table.
The partial query (all but the SELECT TOP 1) is in a private function for reuse in the GetData query code:
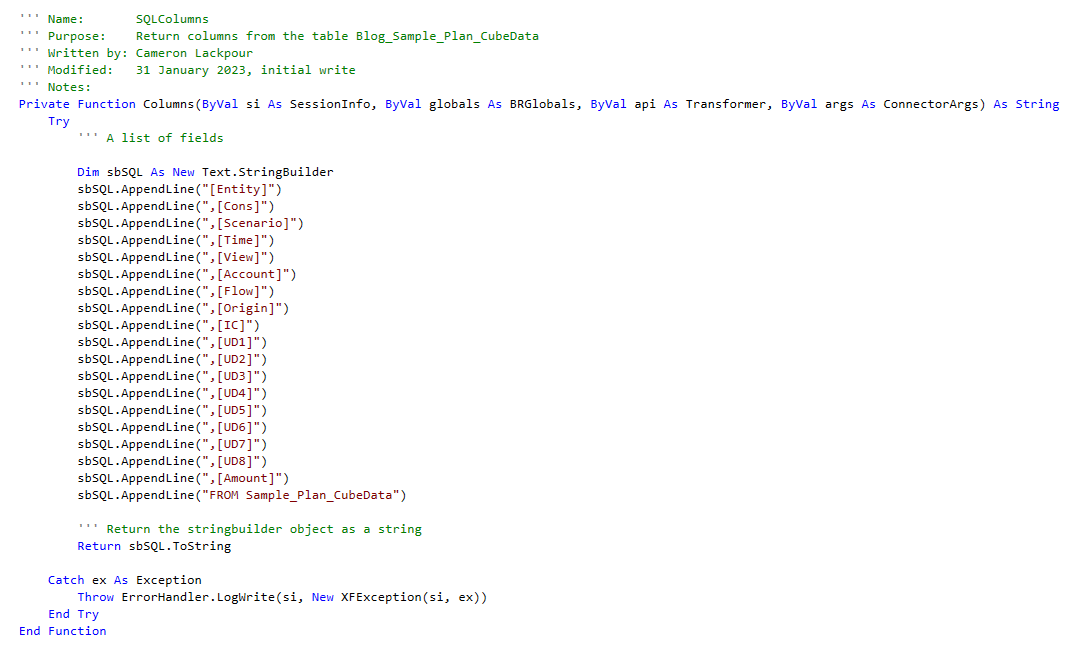
The StringBuilder is passed back to the main code line as a string:

Create the connection – again, this is an internal-to-this-application’s-SQL Server-database:

And then simply execute the query which returns just the first record to get those field names:

If you hover the mouse (Mouse? I use a trackball. Whatever.) over the GetFieldNameListForSQLQuery method, you’ll see most of the parameters sort of make sense:

Note the Return keyword: whatever calls this rule and ActionType will return the fields as a List(Of String), just as if they had been explicitly added in code. No one ever said I did things the easy way. In my defense, there are eleventy million ways to fulfill a requirement in OneStream and which is best is situational or down to preference.
GetFieldList’s code in full, less the private function Columns which is called by Me.Columns:
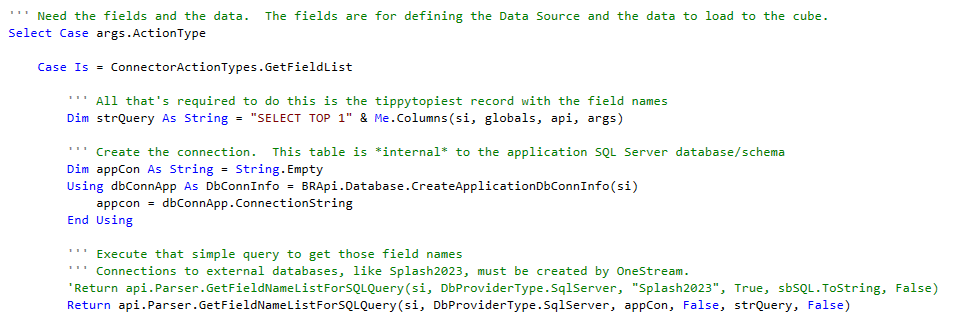
To recap: create a list of fields, create a connection, execute a query that returns the field names. That’s it.
A relational Data Source
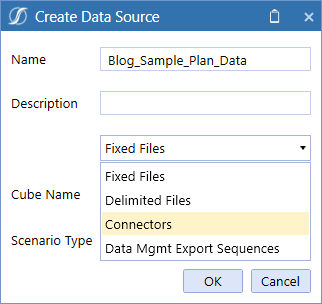
There are File (fixed and delimited) Data Sources, there are Data Management Export Data Sources, and now we see Connector rule-based Data Sources.
Remember, all that the Connector Rule Blog_Sample_Plan_Data does is return a list of fields and, in a bit, the data as well.
In the Data Source properties at the bottom of the screen, select the Connector Business Rule “Blog_Sample_Plan_CubeData”:
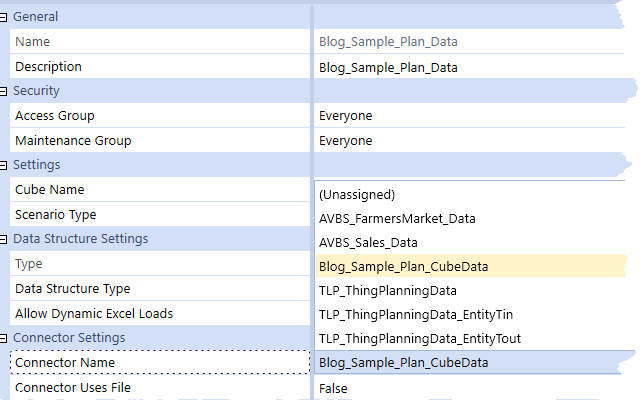
Click on the Save icon and the field list as defined in the Connector Rule show up:
One wonders in vain, but one still wonders
As an aside, when will the 3.5” floppy disk (which is not floppy the way 8” and 5¼ “ disks are) stop being a meaningful icon? I suppose it only matters for those who remember, and the Youth Of Today just know it as, “That weird icon I click on to save stuff” and won’t care where it comes from. But I digress. Again. It was ever thus.
Et voilà! The fields we’ve struggled so much to see.
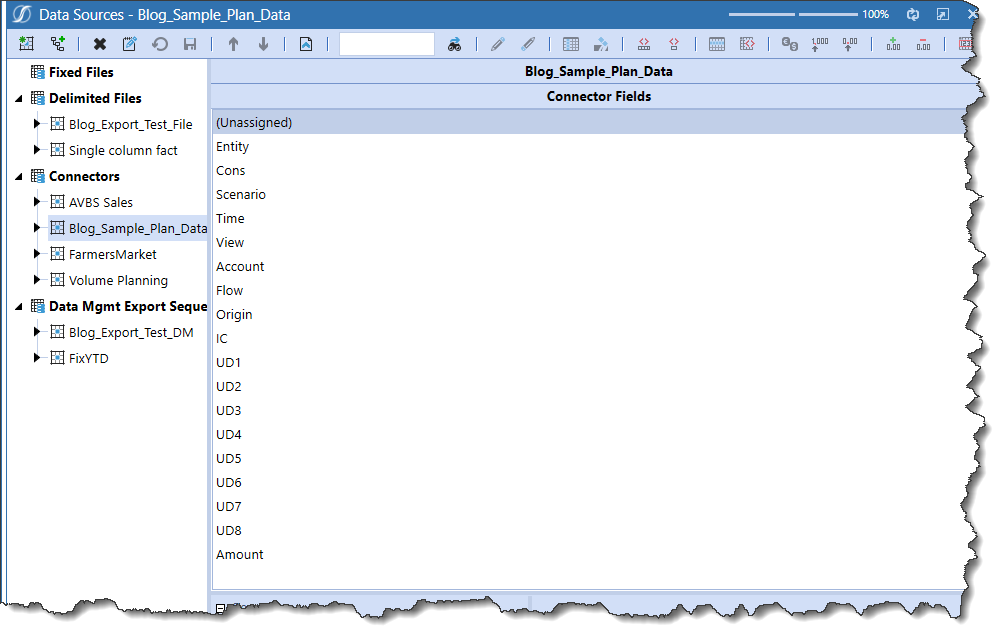
It’s now just a question of lining up the fields with Sample’s dimensions:
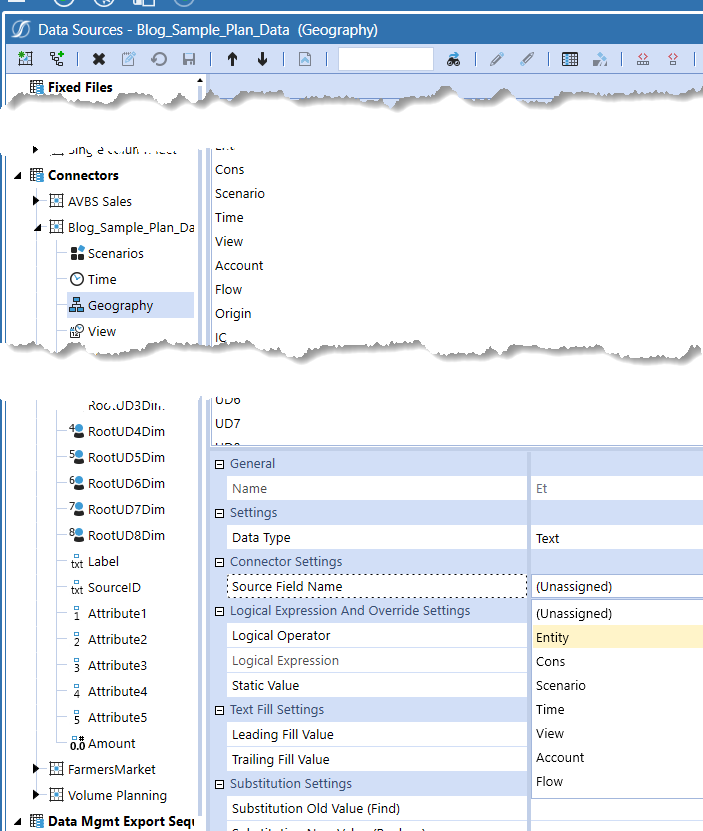
You’ve done this before, or at least I’ve done this before in the service of this blog series on data. That’s it.
Data, data, data
A Data Source is good; data is just as valuable. Hence, back we go the Connector Rule Blog_Sample_Plan_CubeData, with joy in our hearts, a happy song on our lips, and a not-terribly-huge amount of code in our future.
ConnectorActionTypes.GetData
The code is largely the same as GetFieldList but with the ProcessSQLQuery method:
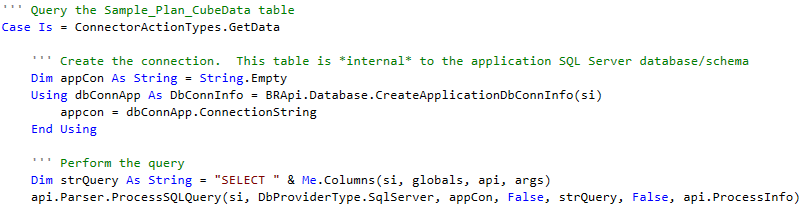
The strQuery is different but only in losing the “TOP 1” modifier. api.Parser.ProcessSQLQuery is identical to GetFieldNameListForSQLQuery except for the last api.ProcessInfo property:

To recap: create the connection (I did this out of order compared to GetFieldList just to show that code doesn’t have to be in duplicate), create a query, execute said query. That’s it, again.
YAWFPC aka Yet Another WorkFlow Profile Child
We’re in the home stretch: create a simple WorkFlow Profile Import Child and connect the just-created relational Data Source and the existing Transformation Rule DMExport, remembering to set Can Load Unrelated Entities to True:
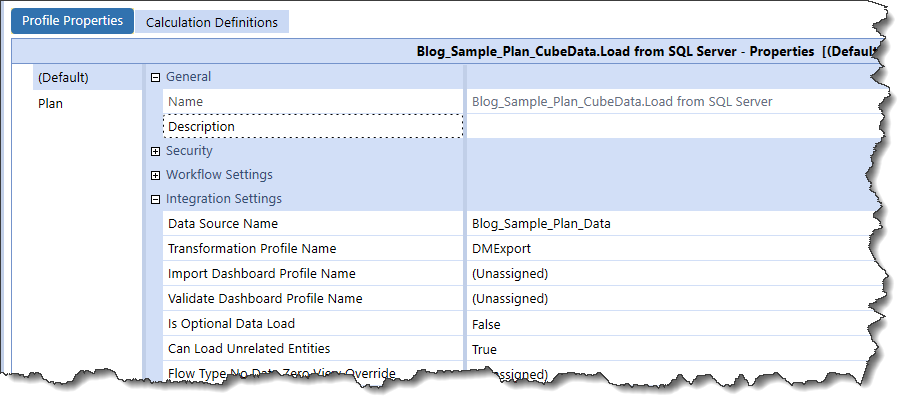
Let ‘er rip
A nice empty Import step:
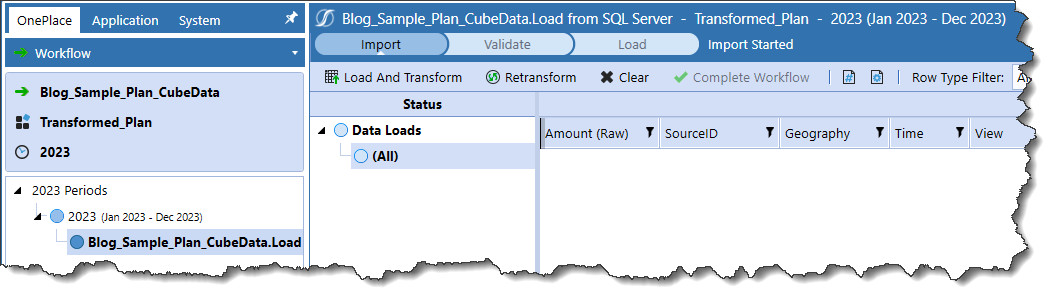
This is no file load:
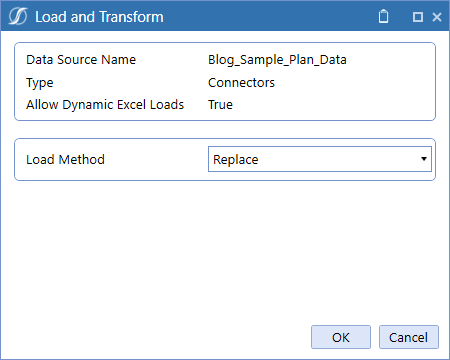
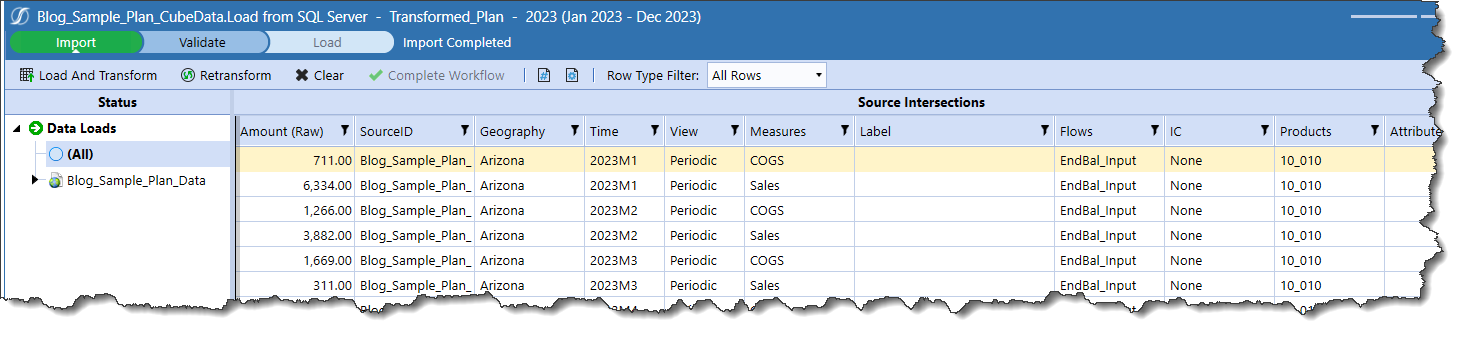
Kick off the load and see a successful Import step:
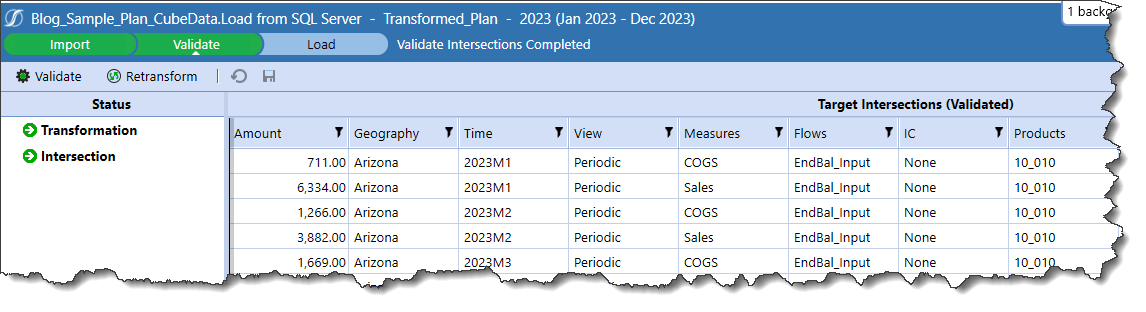
And Validate:
And Load:
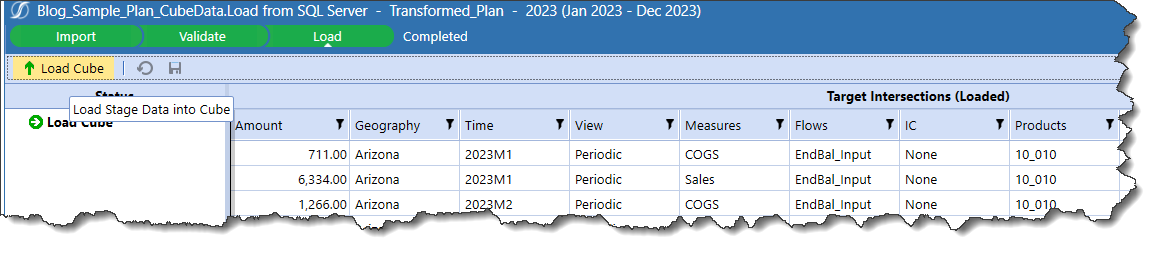
That’s it. Again.
It really is pretty easy, isn’t it
I will confess being flummoxed by the difference the code and configuration needed for internal-to-the-OneStream-application-database vs. external database connections, but You Know Who helped me with that one. He helped me and I’ve (hopefully) helped you, and here we are: a relational data load that is easy as pie, sweet as sugar, and does not rely on unreliable files. I love relational data sources. You should too.
This series isn’t over with yet, no matter how much you may wish it. The next time round I’ll show how simple it is to go after external data sources and load them just as above and perform equally simple transformations in source (a database technology that handles billions of records will, ceteris paribus, outpace even the fastest OneStream Parser Rule or Complex Expression).
If you don’t agree with me re the overall superiority of relational data (oh, I am sure you can come up with edge use cases, but they are just that: edge), contact me and I’ll see if I can win you over.
One last comment: if your existing, flexible, performant, and all around just-great-isn’t-it OneStream system has 25 separate file Data Sources and everything is tickety-boo, for the sake of all that is good, do not start ripping them all out and replacing them with relational data. Additional data sources? Sure, if it makes sense. New application? I’d give them some serious thought. Don’t let advocacy trump prudence.
Be seeing you.