
Setting the stage
We are – finally – at the end of the hey-gang-let’s-have-fun-and-load-data-in-OneStream saga. Never let it be said that Yr. Obt. Svt. cannot take the thinnest of gruel and milk it for all its worth and more as it’s been almost three months of this folderol. But fear not, for we have, hopefully for all concerned, come to an end of this series on data loading.
With that happy thought, let us turn to the subject of not loading data but getting rid of it.
Not quite Act 5, Scene 1, but close
Gentle Reader, don’t clutch your pearls after reading this post’s title; instead recall the salad days of our youth, alas sadly departed, from whence we learnt the Scottish play that our generally-despised/genuinely-feared 7th grade English teachers rammed down our collective throats. At least we got to hear an adult use a naughty word as you now have read in this post. Rejoice at the subversive nature or despair at the childishness; your choice.
Wrong, wrong, wrong
But the sentiment is real: getting data into OneStream is important – rather more than important for what’s OneStream without data? – but when that data is in the wrong place or is just plain wrong, it’s…well, it’s wrong. And wrong data equals a wrong app which means a wrongfully (or is that rightfully) terminated career. There are a million (okay, not a million, but lots) reasons that loaded data can be bad: incomplete data sets, stale data sources, just-plain-not-even-close-to-correct data, rogue data sets submitted through Excel, &c. The list is long, the sources manifold, the result is the same: wrong.
There is not a week, nor a day, nor an hour to lose.
If it data is wrong, it must be excised, exsanguinated, extirpated, executed, exterminated. In other words: gone.

Dead easy
In Stage, it’s easy. A wee bit (or rather a lot – it all depends on your tolerance for risk) dangerous, but easy, and what’s life without that frisson of danger?
One cannot deny one has been warned. Does one pay any attention to it? Maybe? I care not, for I am a roguish devil-may-care sort of geek. Also, I’m writing a blog post on deleting data, so yes, of course the nuclear option is my choice.
Gone.
But is it?
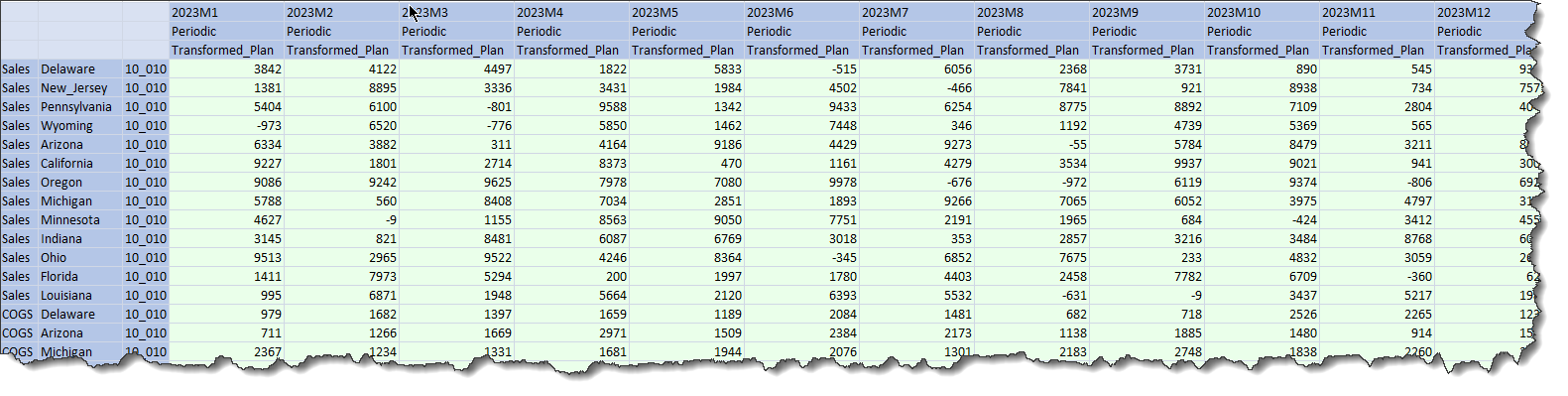
Nope, or at best only half, and arguably the more important bit is cube data which clearing Stage data does not affect. Oh dear, oh dear, oh dear.
Data Buffer to the rescue
A serious note: if there is one element of Finance Business Rules we OneStream practitioners must, must, must master, it is the Data Buffer, for it is the key to performance, flexibility, power, and good practice. I have suffered the worst code in the world or at least code that took forever to run because it did not exploit Data Buffer operations. We shall return to this subject again and again and again until all of we happy few, every man jack of us, perform naught but Data Buffer logic.
A further note: yes, a Clear Data Data Management job can clear data as can a Reset Scenario step but they are the bluntest of axes when it comes to scope and are slow to boot. Additionally, a Clear Data step cannot clear Stage.
All Data is divided into three parts, one of which is a parametrized member list, the code another, those who in their own language is called a Data Buffer, in our Data Management step the third. I’m not sure if this technique is a direct analogue of Ceasar’s conquest of Gaul, but perhaps it’s close.
I’ve got a little list
While data scope in the form of dimensions and their members could be hardcoded within a Data Buffer definition, that’s inelegant at best (what happens when the members to be cleared are different?) and dangerous (ibid., when idiots like me dive into code and change things he oughtn’t). A better approach by far is to create a list that can be changed without mucking about with code.
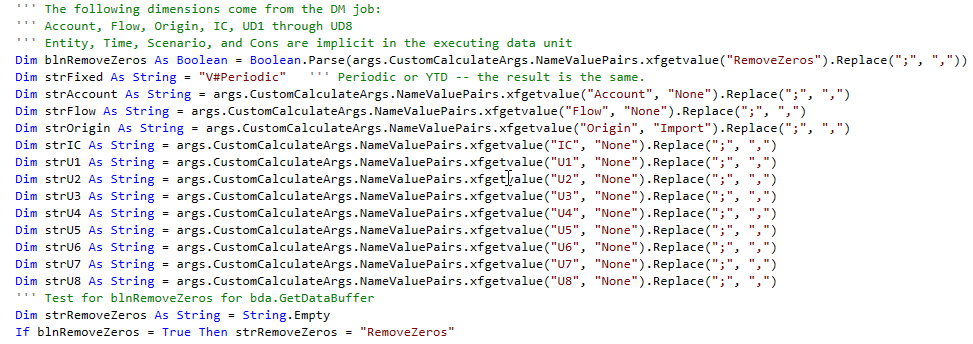
Parameter lists in Data Management steps must be comma-delimited which is fine and dandy except when a dimension member list is needed which – of course – must be comma delimited as well. When args.CustomCalculateArgs.NameValuePairs.xfGetValue interrogates the parameter, it treats each comma delimited member as another parameter argument. Cue the chaos that is prevalent in my life, both professional and personal.
The solution is simple: use ; characters to delimit arguments and then a .Replace(“;”, “.”) method with the string xfGetValue returns:

Note that xfGetValue uses both a parameter argument and a default value just in case the parameter is not passed. This means you (me) can be lazy and not pass all of the dimensions but again that is sloppy, shoddy, and silly practice. Don’t, just, don’t.
Here’s my dimension/member list:
RemoveZeros=True, Account=A#Margin.Base; A#Distribution, Flow=F#EndBal_Input, Origin=O#BeforeAdj.Base, IC=I#None, U1=U1#10_030; U1#10_020; U1#10_010, U2=U2#None, U3=U3#None, U4=U4#None, U5=U5#None, U6=U6#None, U7=U7#None, U8=U8#None
Note Account’s members with a ; between A#Margin.Base and A#Distribution. Also note that because this is merely a string passed back to the calling code, member functions such as .Base are possible. Powerful medicine.
A final note on dimensionality: the Data Unit dimensions Entity, Cons, Scenario, Time, and of course the Cube are not passed to the Business Rule because the Data Buffer implicitly executes with the Data Unit and thus there is little point in explicitly defining them as an argument.
Within the ClearData function (this code could run without a function as the whole class if so desired), here’s the full read of the parameter’s arguments:
That Data Buffer thingy
It is now the work of a moment (or perhaps string interpolation) to pull the dimension members into the Data Buffer definition and of course looping of the Data Buffer itself, clearing within said loop, and a write to disk:
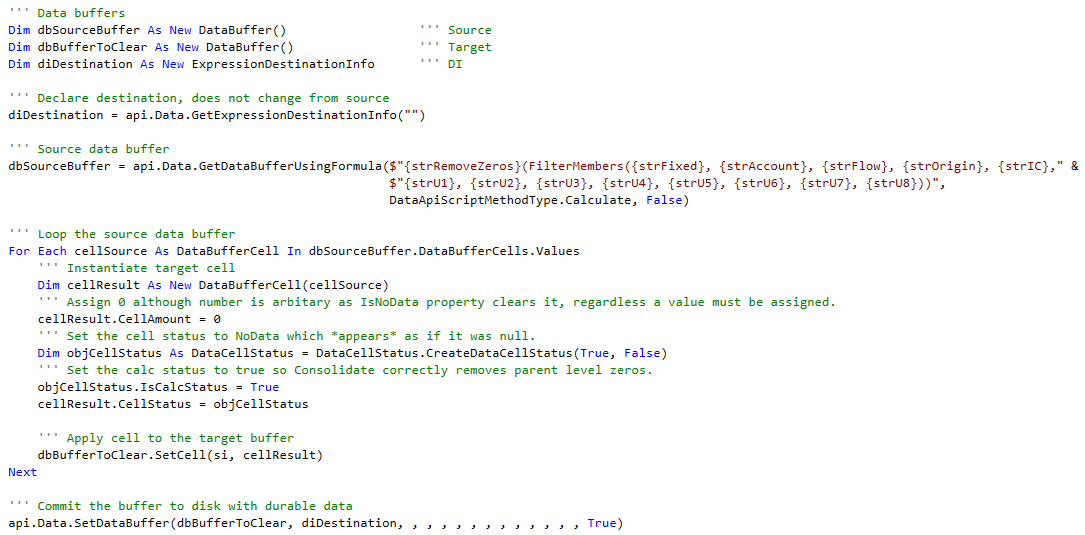
That’s it.
Custom Calculate
Only the Data Management step itself remains:
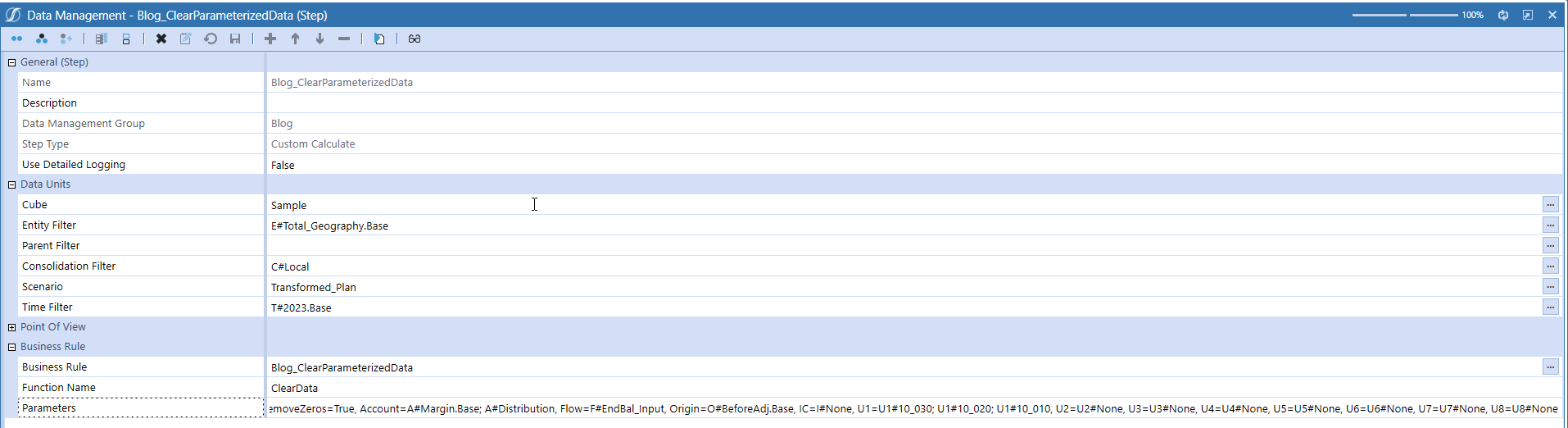
Apologies for the teeny-tiny text, but I wanted to show you the whole shebang. And I did.
The proof of the pudding, as always, is in the eating
Run the Data Management step:
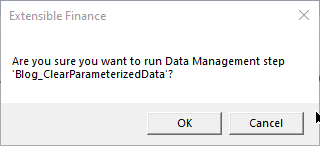
As quick as a fox:
Really, it’s just about as fast as fast can be as Data Buffer operations are fast, fast, fast.
That cube data is, as promised, gone daddy gone:

Clearing Stage is the work of a moment as shown at the tippy-top of this post. Clear data in both locations and your Cube’s data is now a tabula rasa.
Just one more thing

This approach still requires dull and dreary direct data definitions (writing that amount of alliteration was strangely satisfying) within a Data Management step. A dashboard driven data definition (Ibid.) would be nicer. Let’s see if I can manage to do just that in a later post. Maybe.
Be seeing you.[vc_row css=”.vc_custom_1677091392830{margin-top: 20px !important;}”][vc_column][vc_video link=”https://youtu.be/sB-jlomZhHU”][/vc_column][/vc_row]