
There’s a First Time for Everything
Yr. Obt. Svt., in his so-called OneStream career (much like the rest of his so-called career and life and who knows what else), has stuck, largely, to the straight and narrow. Mostly. Why, beyond a marked absence of curiosity? Mostly (in OneStream) because even the basics can be a little overwhelming given its platform nature. I never seem to exhaust the features and functionality of this product and I suspect I never will. I imagine that you too will never truly master all of OneStream. It is actually – kinda – exciting to be faced with so many options when it comes to fulfilling a technical puzzle.
Imagine (eh, be absolutely stunned is a better choice of words) how surprised I was when I found you can load to something other than a Cube within OneStream’s native functionality. Yes, I’ve loaded to custom tables which is fine and dandy if you have table creation rights and the skills to manage uploads of text files (or whatever) to said columns. But what if you don’t? What if there’s a need to upload a limited scope of data (or a rather large one, of which more anon) that needs to be addressable within code but not loaded to a Cube and then do the whole thing through Workflow?

Import (Stage Only) and Stage’s Many Components
The answer is to treat Stage (this is OneStream’s stage environment, not your data mart/warehouse/lake’s staging tables) as a place to load data and then just stop. No Cube, no transformations necessary (albeit possible), no validations because there is no Cube to validate against, etc. In short, it looks an awful lot like a custom table, albeit not a truly unlimited one.
Great Googly Moogly, oh, Import (Stage Only), where have you been all my life (or at least since October 2017 which is when I went to work for OneStream)?
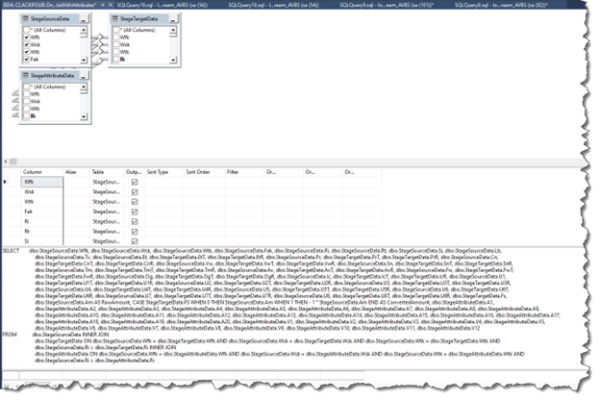
There are 19 (!) Stage tables and five (not so ! but still…) Stage views. I cannot (and, as noted I am quite lazy, so will not) cover all of them – for the purposes of understanding how Import (Stage Only) works, we need only worry about the tables (and we’re not really going to worry about them) StageSourceData (arguably), StageTargetData, and StageAttributeData and for views it’s just vStageSourceAndTargetData and vStageSourceAndTargetDataWithAttributes.
What Could Possibly be Simpler?
vStageSourceAndTargetDataWithAttributes contains everything (and a bit more) we need: where data came from, what said data has been transformed into, data by month in a multicolumn fact layout, and even the year.
Happily, OneStream creates this for us and all we need do is load to the underlying tables and query here. Good grief it’s a bit complicated, but then again I am no SQL developer and you don’t need to be either:
Stage Attributes != Cube Attributes, Except You Define Them in the Cube
Some mothers do ‘ave em’, don’t they. Stage attributes are not attribute dimensions except they are called, “Attribute Dimensions” and “Attribute Value Dimensions”. Yes, they have the word “attribute” and the word “dimensions” and in fact are combined, but one type of Attribute Dimensions is in Stage, not a Cube, and the other (newer) Attribute Dimensions are in a Cube and not Stage. Confused? I am or at least I was. Seriously, coming from Another Technology where attribute dimensions are just cube dimensions, this nomenclature blew my mind.
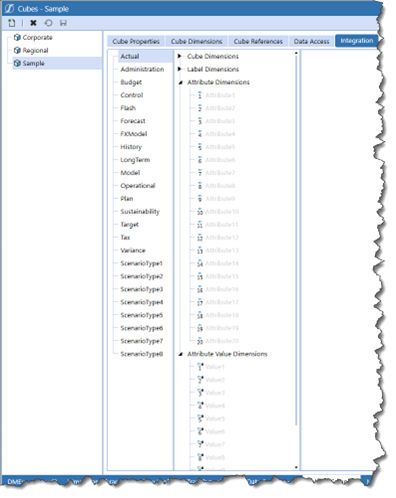
What is more confusing is that turning Stage attributes on (on = addressable in Data Sources and thus can be loaded into Stage) is performed in the Cube’s Integration properties when these Attribute Dimensions aren’t actually in the Cube:
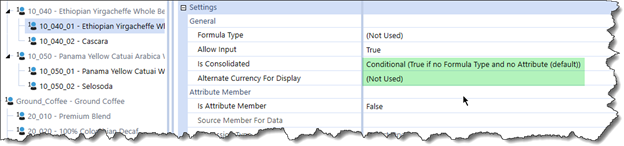
Which is most definitely not the same as a proper dimension in a Cube (although Attributes in Stage can be used as an attribute dimension in BI Blend):
Oh dear.
Did I mention that member all sorts of member properties are commonly called, “attributes”?
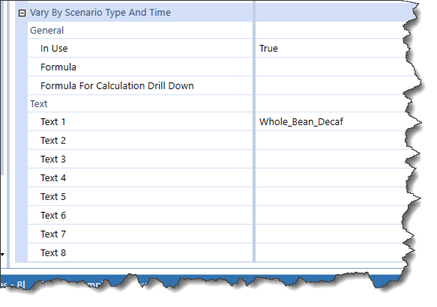
Is this another Cameron Rant (well, yes, this whole blog is one) or at least a Cameron Mistake (Ibid.)? Nope:

Oh dear, redux.
Let’s Try to Bring Order to Chaos
Attributes in Stage are data attributes, whether “Attribute Dimensions” or “Attribute Value Dimensions” (yes, there are text and numeric fields and yes, one could store numeric data in the text Attribute Dimension fields although not the other way round). Never, ever, ever let it be said that OneStream is not flexible. Also, OneStream seems to be in love with the word, “attribute” which is sort of the antithesis of terminological flexibility. It takes all kinds to make the world go round.
Data Attributes in Stage
The whole point of using Import (Stage Only) is to use Workflow to load data to Stage and do nothing more.
After all of this palaver over data attributes, they are not required because Import (Stage Only) can write solely to Cube dimension fields. However, when trying to do this I’ve run out of fields, no one has been able to tell me not to use data attributes or at least tell me that there’s a huge performance hit to using them (although I can see that as a possibility), and I like flexibility, so Stage with data attributes it is.
Let’s Turn Them On
It’s as easy as 22 / 7 for the fractionally minded or 3.142857142857143 for those of a decimal nature.
Go into Cubes->Integration and simply flip the Enabled property (note the absence of the word “attribute”) to True:
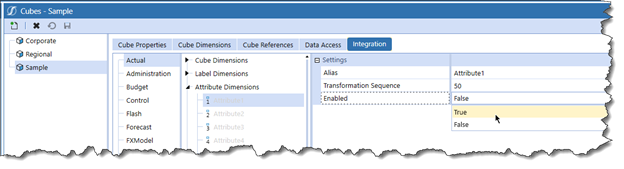
For the purposes of this series, I’ll enable eight text data attributes and one data value attribute to support the fields I need in the Plan scenario type. Arguably, the data value attribute is redundant because of the required Amount field that could carry the data:
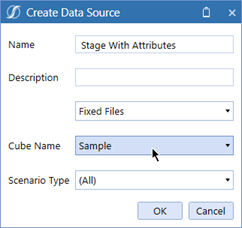
Enabled in Data Source
Yes, you do have to assign it to a Cube. No, a Cube isn’t really relevant in the data itself but it is needed for Workflow, hence the assignment:
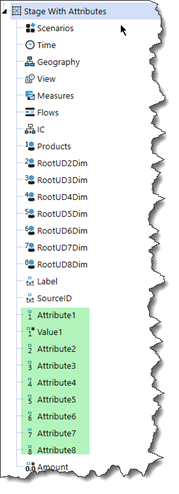
Here they automagically are:
And That’s Where We Stop
All of this has been prelude to actually loading data to Stage. The Data Source itself (and its sort-of-odd required values) and Workflow, and transformations (yes, they are possible, sometimes) are grist for the next post.
Be seeing you.