
Big Oops
Little – or big – things can have an impact. Sometimes they are a (gasp) Ferrari 308 in a ditch, sometimes they are data where data should never, ever, ever be. Double gasp.

Data where it shouldn’t be? How oh how oh how could that be? Not in OneStream, surely?
Just like hitting an icy patch on summer tires at what might be extra-legal speeds, simple mistakes in, oh, say, a Data Management step can lead to all sorts of trouble. In fact, it can be done in one word. I promise you, ‘tis true.
Simple sample data in A Very Basic Sample using C#Aggregated
For we planning-in-OneStream practitioners, aggregating rather than consolidating data is advantageous because of the significant performance gains. Good. Great. Awesome.
Here’s some completely-made-up-just-for-this-use-case level 0 data:
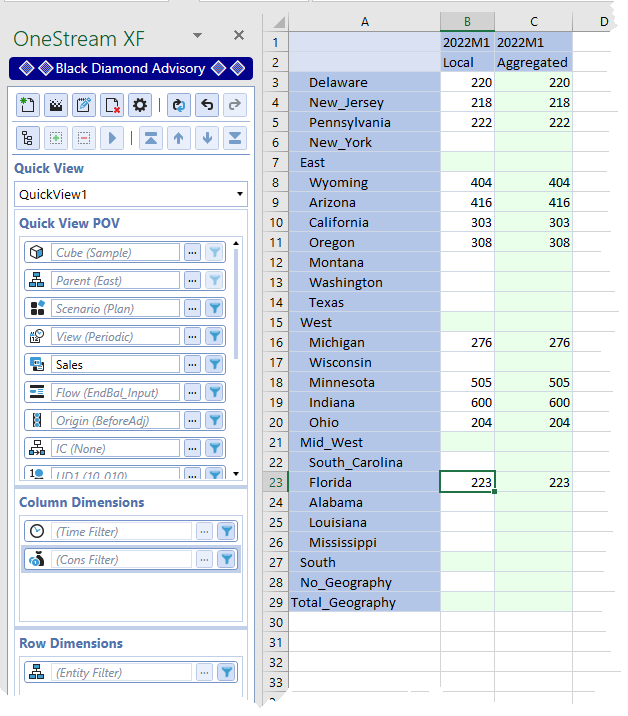
Notice that C#Aggregated automatically reflects level 0 C#Local data. This Data Management Step:
Results in this very satisfactory result:
Level 0 data is in C#Local, aggregated data is C#Aggregated; there is no upper level data in C#Local. With C#Aggregated, you (Yr. Obt. Svt.) are (is) trading data in one Consolidate dimension member for improved performance. Make no mistake: C#Aggregated is many times faster than C#Local. If your application doesn’t need true consolidation, aggregation is the way to go, unless watching paint dry is your thing.
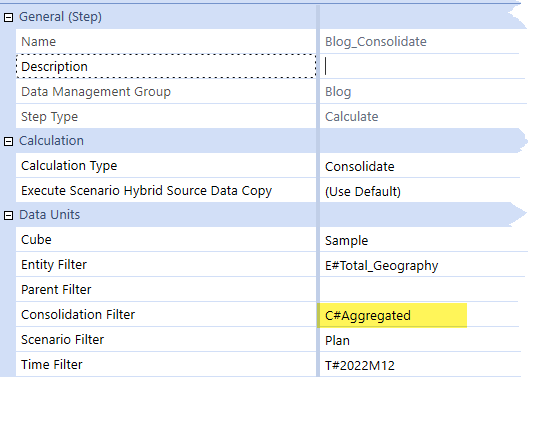
All is good. However, what happens if there is another Data Management step that is truly a consolidation? It’s just a simple mistake, and an easy one to make as base data is stored in C#Local:
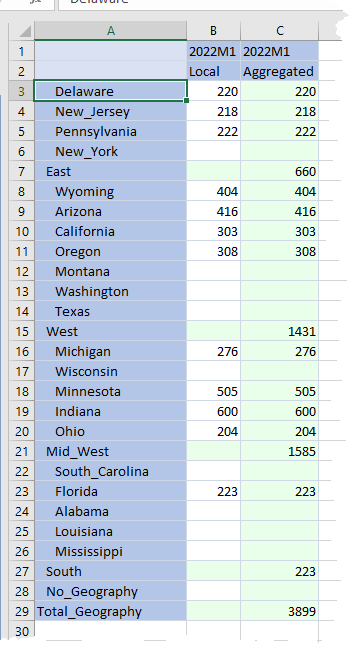
Data is redundant, but correct:
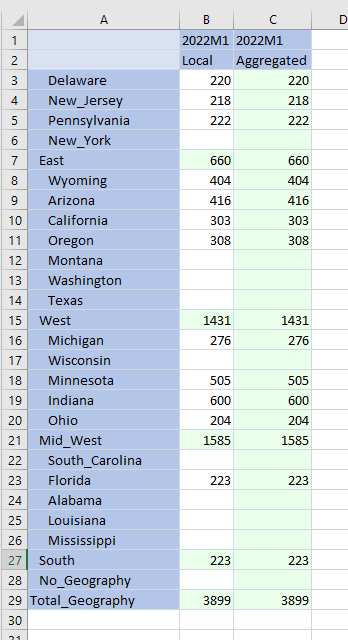
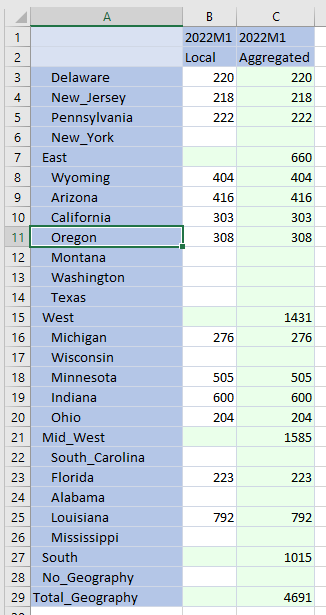
This is a Bad Thing: storage overhead of the same data twice is made worse by the potential for level 0 data changes that may not be reflected in C#Local or C#Aggregated depending on which Data Management step is run, e.g. if Louisiana receives a value of 792, the correct total of 4,691 is now in C#Local:E#Total_Geography but not in C#Aggregated:E#Total_Geography. C#Aggregated:E#South isn’t right, either.
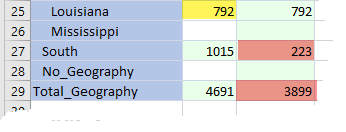
Users (or consultants) can all too easily pick C#Aggregated and get the wrong answer. Actually, C#Aggregated member should have that new total and C#Local above the base level should be blank. But the parents in C#Local are valued. Only The Shadow Knows which member will be used. Ouch.
Of course, OneStream practitioners are forthright, diligent, and kind-to-their-mothers geeks, so we’d never make that mistake.

Except of course we all do splendid things like this, no matter our best intentions. Little things can mean a lot.
Fixing things. Maybe.
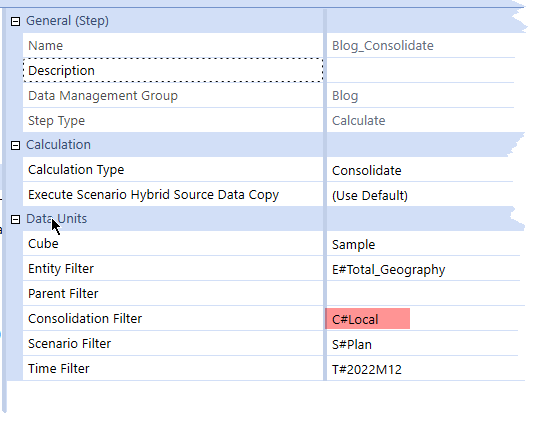
The first step, after of course unfairly fixing the blame on anyone but yourself, is to root out the offending Data Management Step(s) and change them (it) to C#Aggregated.
What about the bad data in E#South:C#Local and E#Total_Geography:C#Local and the redundant data in the other regions of these United States?
The key is to select those upper level Entities and get rid of their data values. Aggregated numbers belong only in C#Aggregated.
As per my blog post on member functions, it’s trivial to get just those upper level members using member filters:
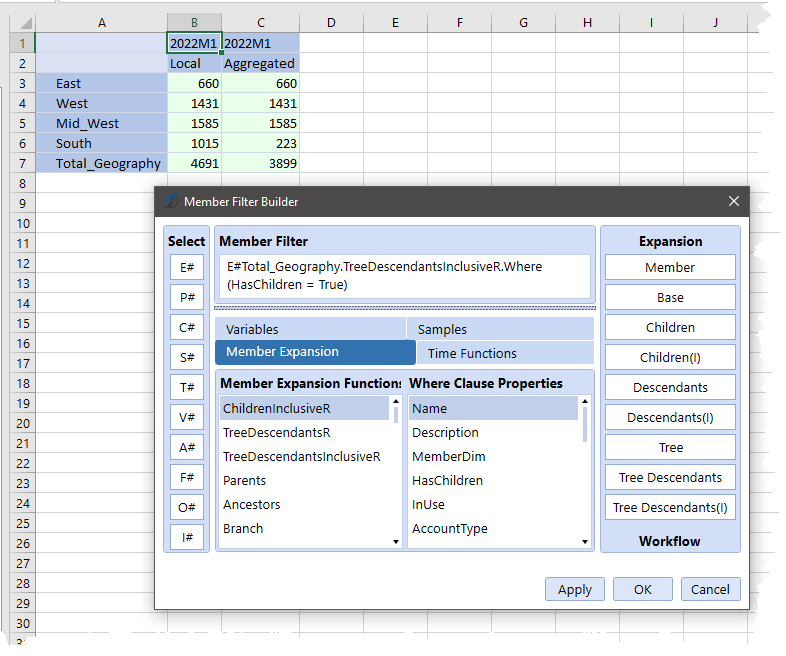
NB –The key bit is the .Where(HasChildren = True) clause to skip all of the level 0 members which after all cannot have children.
DataBuffer to the rescue. Again. Of course.
DataBuffers are usually the fastest way to traverse data. Clearing data is something data buffers are particularly good at because they explicitly address the data intersections that have data.
Search and destroy
I set up a Custom Calculate Data Management Step that runs the Finance Business Rule Blog_ClearData:
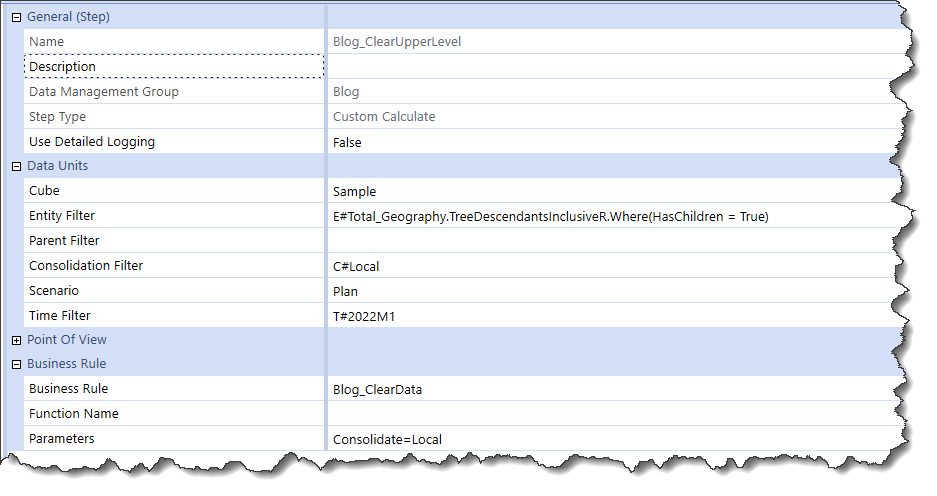
This step passes the Consolidate dimension member as a parameter in case C#Local is desired and some genius planning dude thought that he should do everything in C#Aggregated. You (and I) know what could happen likely will and perhaps has. Keep things flexible, Gentle Reader.
Setting up the buffer is old hat by now for loyal readers of this blog.

Within the buffer itself:
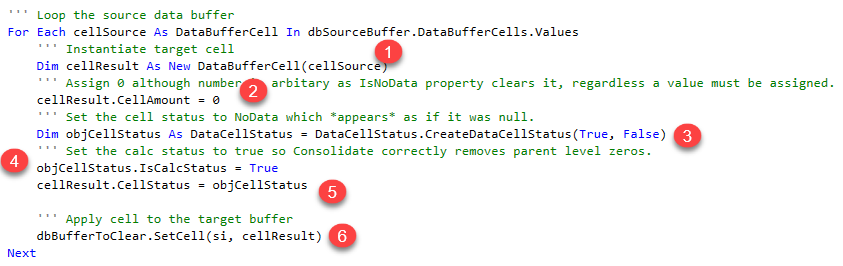
- Instantiate a result cell
- Set that cell’s CellAmount to 0 (although it could be 42 as it’s going to get zapped)
- Instantiate a DataCellStatus object and set its status to NoData

- Set that object’s calc status to True to ensure that the consolidation process really adds things up
- Set the result cell’s CellStatus to the NoData/calc status properties
- As always, apply the cell to the data buffer
The revised data buffer is now in memory – write it to the cube using Durable Data although arguably within this use case preserving data on consolidation is pointless because getting rid of that data is the very purpose of this blog post. I think it’s a good habit so I consistently do it:

Kill it with fire
Run the rule:
Did it work?
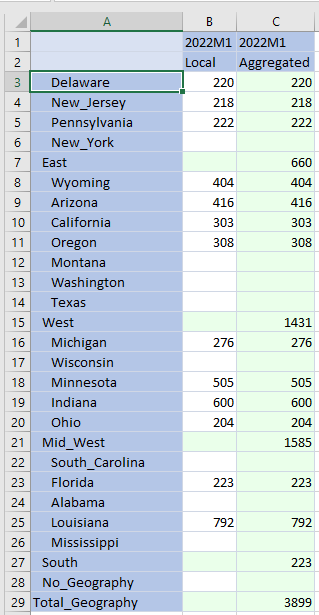
Yep.
Aggregate away
Run that consolidation that points at C#Aggregated and the right totals appear:
Don’t be that geek
This one really and truly did happen to me as the application I was working on had an errant consolidate step buried away in a Data Management Group “that is never used” except of course it was. Bad Data results in Unhappy Users. Be Unglad to Be Unhappy.
Be seeing you.