
Relational solutions are a powerful tool within OneStream that allows the user to create imaginative implementations, but that same flexibility can also lead to unnecessary complexity if sound database principles are not followed. What starts as a reasonable design quickly buckles under the pressure of an evolving spec—the reality of tech debt is an ever-looming threat that can quietly consume time and resources. It is crucial then to understand basic database design, organizing information logically, and simply through normalization. With enough care, you can prevent a lot of unnecessary headaches as you iterate through your solution to meet your client’s needs through these basic principles!
What is Database Normalization?
Database normalization is a design paradigm that helps define table structure (AKA “schema”) so that each fact is stored in one logical place. A well-formed schema makes data easier to manage, and leaves tables better prepared for change.
Consider for a moment two sets of data:
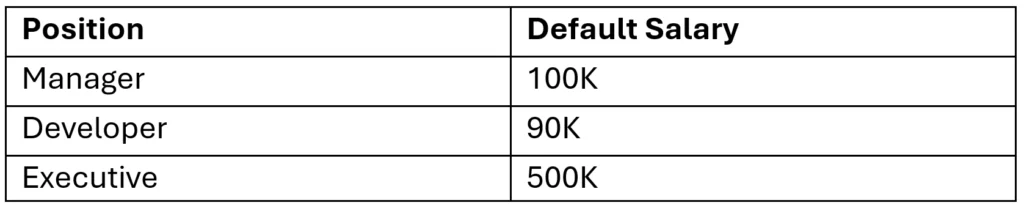
Position:
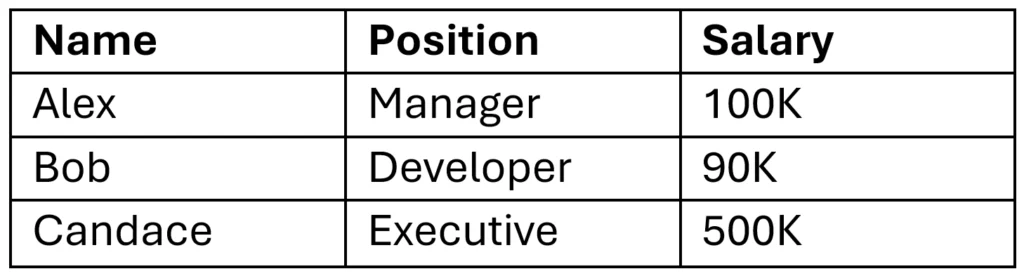
Employee:
A naïve design might repeat employee and position information in a single detail table, such as:
Employee Detail:
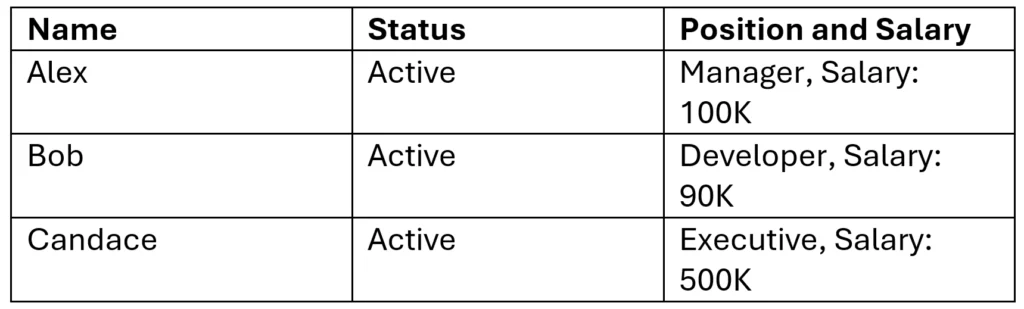
At first glance, this structure may seem sufficient, but it introduces duplication and unnecessary dependencies.
This design introduces several problems:
- Employee names are repeated across tables.
- Position descriptions are repeated across tables.
- Salary is stored alongside position data, even though compensation may vary by employee.
Now suppose Alex’s name changes to Alexander. In this design, that change must be made in more than one place:
- Update Employee Detail Table: find Alex and update Name to Alexander
- Update Employee Table: find Alex and update Name to Alexander
What should be a single update now requires multiple updates, increasing both maintenance effort and the risk of inconsistency.
What if, instead, this database was normalized?
Normalizing a Database
To normalize these tables, we first identify duplicated data. Next, we separate distinct entities into their own tables. Finally, we connect those tables using keys.

A normalized version of this design might look like this:
Position:

Employee:
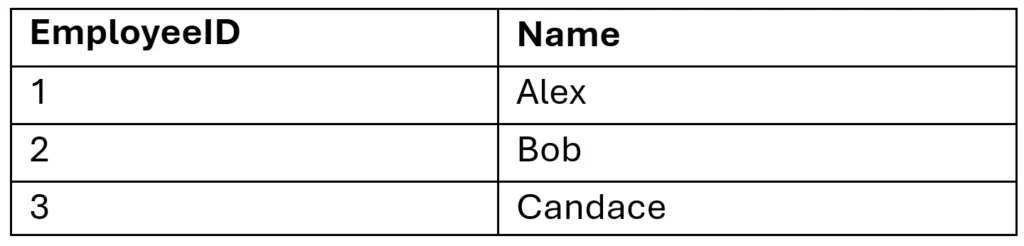
Employee Detail:

In this version, changing Alex’s name to Alexander requires only one update in the Employee table.
The other tables do not need to change, because they refer to Alex by EmployeeID rather than by name (the ID acts as a stable reference to the employee record).
This design also separates position data from employee-specific salary data. If Alex receives a raise, only the Employee Detail table needs to be updated. That change does not affect other employees with the same position.
Likewise, if our ingress file suddenly has a change to include a new column called “Position Grade”, it can be added to the Position table without redesigning the other tables—the query to get the position grade for a single employee then only needs to add the PositionGrade column to the SELECT clause.
This query reconstructs the business view by joining the employee record to the employee’s detail row and position record, including the addition of the theoretical PositionGrade column:

This is a very rudimentary example but it’s easy to imagine a situation where your ingress file has hundreds of thousands of rows with hundreds of details for each row. An update that requires 2 steps instead of 1 has doubled the amount of work for that operation–on expensive operations, this performance hit is very real and appreciable, so be careful with how you design your tables to mitigate unnecessary operations!
I do want to point out that although this example uses employee roster data, the same principles apply broadly across database design. The same normalization logic can be used for stored parameters, UI configurations, and many other relational structures, and these principles are fundamental to database design. You may also notice a very similar structure when inspecting OneStream’s native tables, so take notes!
Theoretical Normalization and Reality
In a perfect world, we would take normalization to its logical end point to keep the data clean and organized.

Unfortunately, the reality is that normalized tables don’t necessarily result in performant code. For example, if every attribute in Employee Detail were broken into separate related tables, even a simple business query might require a large number of joins. Although that structure may be logically clean, each additional JOIN adds more overhead for the SQL optimizer and execution engine. Because SQL is declarative, the optimizer determines the execution plan, and complex queries do not always perform as expected. Factors such as table size, indexes, table scans, I/O speed, and cache pressure can all affect the speed at which a query runs which is largely out of direct control of the query itself.
For read-heavy use cases such as reports, dashboards, or repeated summary queries, it may be practical to denormalize selected data for performance.
Some techniques to denormalize data include:
- Merge Related Data: If two attributes are almost always retrieved together, it may be reasonable to store them together in a reporting or staging table to reduce join overhead.
- Create Summary Tables or Materialized Views: Frequently accessed aggregates, such as balances, counts, or report-ready summaries, can be precomputed to improve read performance. Be careful when implementing this if the underlying data is something that changes often—you must consider the overhead associated with maintaining the summary table every time the underlying data changes.
- Intentionally Duplicate Data: In reporting tables, it can be useful to copy reference attributes such as position name, department, or category so that the report does not have to reconstruct them through repeated joins.

In Conclusion
In practice, normalization provides a clean, reliable foundation for a database by reducing duplication and preserving consistency, while denormalization is a targeted optimization used when real-world performance demands faster reads than a fully normalized design can easily provide.
The key is balance: design the data model for correctness first with normalization, understand the theoretical structure behind it, and then selectively introduce summaries, redundant fields, or precomputed views only where they clearly improve usability, scalability, and response time.